배경
작업 자원 요구 사항을 예측하는 것은 엔터프라이즈 클러스터에서 여전히 중요하고 도전적인 문제입니다. 이는 기존의 일괄 작업에서 대화 형 쿼리에 이르기까지 스트리밍 및 최근 기계 학습 작업에 이르기까지 끊임없이 증가하는 작업량의 복잡성으로 인해 더욱 확대되었습니다. 결과적으로 Tez, MapReduce, Spark 등과 같은 여러 계산 프레임 워크에 의존하는 작업이 발생하고 클러스터의 특성을 공유함으로써 문제가 더욱 복잡해집니다. 현재의 최첨단 솔루션은 지루하고 비효율적 인 작업 (예 : 감속기 또는 컨테이너 메모리 크기 등)에 대한 자원 요구 사항을 예측하기 위해 사용자의 전문 기술에 의존합니다.
클러스터 워크로드 분석을 기반으로 60 % 이상의 많은 일자리가 반복되는 일자리로 기록 작업을 기반으로 작업 리소스 요구 사항을 자동으로 예측할 수있는 기회를 제공합니다. 일자리는 대개 다른 계산 프레임 워크에서 나왔다는 점에 주목할 필요가 있습니다. 또한 버전은 실행 과정에서 변경 될 수 있습니다. 따라서 우리는 재귀 작업에 대한 자원 요구 사항을 자동으로 추정하기 위해 프레임 워크에 무관심한 블랙 박스 솔루션을 제안하고자합니다.
목표
- 정기적 인 작업의 경우 기록 로그를 분석하고 새 실행에 대한 리소스 요구 사항을 예측합니다.
- 다양한 작업 로그를 지원합니다.
- 테라 바이트 단위의 작업 로그로 확장하십시오.
아키텍쳐
다음 그림은 리소스 견적서의 구현 아키텍처를 보여줍니다.
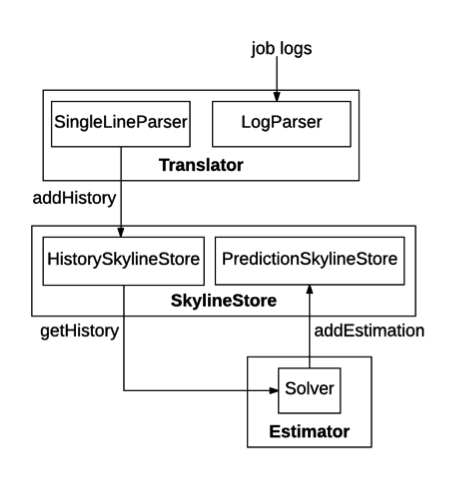
Hadoop-resourceestimator는 주로 Translator, SkylineStore 및 Estimator의 세 가지 모듈로 구성됩니다.
- ResourceSkyline 은 수명 기간 동안 작업의 자원 활용을 특성화하는 데 사용됩니다. 보다 구체적으로 RLESparseResourceAllocation ( https://github.com/apache/hadoop/blob/b6e7d1369690eaf50ce9ea7968f91a72ecb74de0/hadoop-yarn-project/hadoop-yarn/hadoop-yarn-server/hadoop-yarn-server-resourcemanager/src/main)을 사용합니다. /java/org/apache/hadoop/yarn/server/resourcemanager/reservation/RLESparseResourceAllocation.java ) 컨테이너 할당 정보를 기록합니다. RecurrenceId 는 재귀 파이프 라인의 특정 실행을 식별하는 데 사용됩니다. 파이프 라인은 여러 작업으로 구성 될 수 있으며 각 작업에는 리소스 사용률을 특성화 하는 ResourceSkyline 이 있습니다.
- Translator 는 작업 로그를 구문 분석하고 ResourceSkylines를 추출 하여 SkylineStore에 저장합니다. SingleLineParser 는 로그 스트림의 한 행을 파싱하고 ResourceSkyline을 추출합니다 . LogParser 는 SingleLineParser를 사용하여 로그 스트림의 각 행을 재귀 적으로 구문 분석합니다 . 로그에는 다른 저장 형식이있을 수 있으므로 LogParser 는 File 또는 다른 형식 대신 입력 스트림으로 문자열 스트림을 사용합니다. 작업 로그에는 다양한 형식이있을 수 있으므로 다른 SingleLineParser 구현이 필요하므로 LogParser 는 SingleLineParser를 시작합니다사용자 구성을 기반으로합니다. 현재 Hadoop-resourceestimator는 SingleLineParser에 대해 두 가지 구현을 제공합니다 . NativeSingleLineParser 는 최적화 된 기본 형식을 지원하고 RMSingleLineParser 는 Hadoop 시스템에서 생성 된 YARN ResourceManager 로그를 파싱합니다. RM 로그는 프로덕션 배포에서 널리 사용 가능 하므로 파싱됩니다.
-
SkylineStore 는 Hadoop-resourceestimator의 저장소 계층 역할을하며 두 부분으로 구성됩니다. HistorySkylineStore 는 Translator가 추출한 ResourceSkylines을 저장합니다 . addHistory, deleteHistory, updateHistory 및 getHistory의 네 가지 작업을 지원합니다. addHistory는 새 ResourceSkylines 를 재귀 파이프 라인에 추가하는 반면 updateHistory 는 특정 재귀 파이프 라인의 모든 ResourceSkylines 를 삭제하고 새 ResourceSkylines를 다시 삽입 합니다. PredictionSkylineStore 는 Estimator에서 생성 한 예측 된 RLESparseResourceAllocation을 저장합니다 . addEstimation과 getEstimation의 2 개의 액션을 지원합니다.
-
현재 Hadoop-resourceestimator는 SkylineStore를위한 메모리 내 구현을 제공합니다.
- Estimator 는 히스토리 실행에 따라 반복되는 파이프 라인의 리소스 요구 사항을 예측하고 예측을 SkylineStore에 저장하며 YARN (YARN-5326)에 대한 반복적 인 리소스 예약을 수행합니다. Solver 는 특정 되풀이 파이프 라인의 모든 History ResourceSkylines 를 읽고 RLESparseResourceAllocation에 래핑 된 새로운 리소스 요구 사항을 예측합니다 . 현재 Hadoop-resourceestimator는 LPSOLVER 를 제공 하여 예측을 수행합니다 (선형 프로그래밍 모델의 세부 사항은이 문서에서 찾을 수 있습니다). 예측 자원 요구 사항을 ReservationSubmissionRequest 로 변환 하는 BaseSolver 도 있습니다. YARN에서 반복적 인 리소스 예약을하기 위해 다른 솔버 구현에서 사용됩니다.
- ResourceEstimationService 는 클러스터에 쉽게 배포 할 수있는 마이크로 서비스로 Hadoop-resourceestimator를 래핑합니다. 그것은 사용자가 명시한 작업 로그, 쿼리 파이프라인의 이력 ResourceSkylines 조회, 예측사항이 없다면 파이프 라인의 예측 리소스 요구 사항 조회, SkylineStore에서 ResourceSkylines 삭제를 REST API 로 제공합니다.
사용법
이 섹션에서는 리소스 견적 서비스의 사용 방법을 안내합니다.
여기에하자 $ HADOOP_ROOT는 하둡 설치 디렉토리를 나타냅니다. 직접 Hadoop을 빌드하면 $ HADOOP_ROOT 는 hadoop-dist / target / hadoop- $ VERSION 입니다. 리소스 견적 서비스 $ ResourceEstimatorServiceHome 의 위치 는 $ HADOOP_ROOT / share / hadoop / tools / resourceestimator 입니다. bin , conf 및 data 라는 3 개의 폴더가 있습니다 . 사용자는 기본 구성으로 리소스 견적 기능 서비스를 사용할 수 있습니다.
-
bin 에는 자원 견적 기능 서비스 용 실행 스크립트가 들어 있습니다.
-
conf : 리소스 견적 서비스의 구성 파일을 포함합니다.
-
데이터 에는 리소스 견적 서비스의 예제를 실행하는 데 사용되는 예제 로그가 들어 있습니다.
1 단계 : 예측을 시작
우선, $ ResourceEstimatorServiceHome / conf / 에있는 설정 파일 을 $ HADOOP_ROOT / etc / hadoop에 복사하십시오 .
견적을 시작하는 스크립트는 start-estimator.sh 입니다.
$ cd $ ResourceEstimatorServiceHome $ bin / start-estimator.sh
웹 서버가 시작되고 사용자는 REST API를 통해 자원 추정 서비스를 사용할 수 있습니다.
2 단계 : 예측 실행
자원 추정기 sercive에 대한 URI는 http://0.0.0.0 , 기본 서비스 포트는 9998 (구성 $ ResourceEstimatorServiceHome / conf의 / resourceestimator-config.xml에 ). 에서 $ ResourceEstimatorServiceHome / 데이터 , 샘플 로그 파일이 resourceEstimatorService.txt 2 실점 tpch_q12 쿼리 작업의 로그를 포함하고 있습니다.
- 작업 로그를 파싱합니다. POST http : // URI : port / resourceestimator / translator / LOG_FILE_DIRECTORY
POST http : ///.0.0.0.0:9998/resourceestimator/translator/data/resourceEstimatorService.txt를 보냅니다 . 기본 추정자는 ResourceSkylines를 로그 파일에서 추출하여 jobHistory SkylineStore에 저장합니다.
- 쿼리 작업의 기록 ResourceSkylines : GET http : // URI : port / resourceestimator / skylinestore / history / {pipelineId} / {runId}
보내기 GET http://0.0.0.0:9998/resourceestimator/skylinestore/history/*/*을 하고, 기본 추정 역사 SkylineStore의 모든 레코드를 반환합니다. tpch_q12를 두 번 실행하면 ResourceSkylines : tpch_q12_0 및 tpch_q12_1을 볼 수 있습니다. pipelineId 및 runId 필드 는 모두 와일드 카드 작업을 지원합니다.
- 작업의 리소스 스카이 라인 요구 사항 예측 : http : // URI : port / resourceestimator / estimator / {pipelineId}
보내기 http://0.0.0.0:9998/resourceestimator/estimator/tpch_q12를 하고, 기본 추정기는 역사의 ResourceSkylines을 기반으로 새로운 실행을위한 작업의 자원 요구 사항을 예측하고, jobEstimation SkylineStore에 예측 자원 요구 사항을 저장합니다.
- 쿼리 작업의 예상 리소스 스카이 라인 : GET http : // URI : port / resourceestimator / skylinestore / estimation / {pipelineId}
보내기 http://0.0.0.0:9998/resourceestimator/skylinestore/estimation/tpch_q12를 하고, 기본 추정기는 tpch_q12 작업에 대한 역사 자원 요구 사항 추정을 반환합니다. jobEstimation SkylineStore의 경우 와일드 카드 작업을 지원하지 않습니다.
- delete 작업의 기록 리소스 skylines : DELETE http : // URI : port / resourceestimator / skylinestore / history / {pipelineId} / {runId}
보내기 http://0.0.0.0:9998/resourceestimator/skylinestore/history/tpch_q12/tpch_q12_0를 하고, 기본 추정기는 tpch_q12_0의 ResourceSkyline 기록을 삭제합니다. GET http : ///.0.0.0::9998/resourceestimator/skylinestore/history/*/*을 다시 보내면 기본 추정자는 tpch_q12_1에 대한 ResourceSkyline 만 반환합니다.
3 단계 : 예측 중지
견적을 중지하는 스크립트는 stop-estimator.sh 입니다.
$ cd $ ResourceEstimatorServiceHome $ bin / stop-estimator.sh
예시
여기서는 Resource Estimator Service를 사용하는 예를 제시합니다.
먼저 tpch_q12 작업을 9 번 실행하고 각 실행에서 작업의 자원 스카이 라인을 수집합니다 (이 예에서는 "할당 된 컨테이너 수"정보 만 수집합니다).
그런 다음 Resource Estimator Service에서 로그 파서를 실행하여 로그에서 ResourceSkylines을 추출하고 SkylineStore에 저장합니다. 직업의 ResourceSkylines은 데모를 위해 아래에 그려져 있습니다.

마지막으로 Resource Estimator Service에서 견적을 실행하여 RLESparseResourceAllocation ( https://github.com/apache/hadoop/blob/b6e7d1369690eaf50ce9ea7968f91a72ecb74de0/hadoop-yarn-project/hadoop-label/) 에서 래핑 된 새로운 실행에 대한 리소스 요구 사항을 예측합니다. 원사 / hadoop-yarn-server / hadoop-yarn-server-resourcemanager / src / main / java / org / apache / hadoop / yarn / server / resourcemanager / 예약 / RLESparseResourceAllocation.java )를 사용합니다. 예상 자원 요구 사항은 데모 용으로 아래에 그려져 있습니다.

고급 구성
이 섹션에서는 Resource Estimator Service의 구성을 안내합니다. 구성 파일은 $ ResourceEstimatorServiceHome / conf / resourceestimator-config.xml에 있습니다.
- resourceestimator.solver.lp.alpha
리소스 견적서에는 예측을 수행 할 수있는 통합 선형 프로그래밍 솔버가 있습니다 ( 자세한 내용 은 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/10/osdi16-final107.pdf 참조). )이 매개 변수는 선형 프로그래밍 모델에서 리소스 초과 할당과 부족 할당 사이의 균형을 조정합니다. 이 매개 변수는 0에서 1까지 다양하며 알파 값이 클수록 모델이 초과 할당을 최소화합니다. 기본값은 0.1입니다.
- resourceestimator.solver.lp.beta
이 매개 변수는 선형 프로그래밍 모델의 일반화를 제어합니다. 이 매개 변수는 0에서 1까지 다양합니다. 디 퍼트 값은 0.1입니다.
- resourceestimator.solver.lp.minJobRuns
예측을 수행하는 데 필요한 최소 작업 실행 수입니다. 기본값은 2입니다.
- resourceestimator.timeInterval
작업 실행을 간격으로 이등분하는 데 사용되는 시간 길이입니다. 추정기는 각 구간에 대한 자원 할당 예측을 수행함에 유의해야한다. 시간 간격이 짧을수록 예측을 세분화 할 수 있지만 예측에 더 많은 시간과 공간이 필요합니다. 기본값은 5 (초)입니다.
- resourceestimator.skylinestore.provider
Skylinestore 공급자의 클래스 이름입니다. 기본값 은 skylinestore의 메모리 내 구현 인 org.apache.hadoop.resourceestimator.skylinestore.impl.InMemoryStore 입니다. 사용자가 자신의 skylinestore 구현을 사용하려면이 값을 적절하게 변경해야합니다.
- resourceestimator.translator.provider
번역기 공급자의 클래스 이름입니다. 기본값은 org.apache.hadoop.resourceestimator.translator.impl.BaseLogParser로 , 로그 스트림에서 자원 변수 를 추출합니다. 사용자가 자신의 변환기 구현을 사용하려면 적절하게이 값을 변경해야합니다.
- resourceestimator.translator.line-parser
로그의 단일 행을 구문 분석하는 변환기 단일 행 구문 분석기의 클래스 이름입니다. 기본값은 org.apache.hadoop.resourceestimator.translator.impl.NativeSingleLineParser 이며, 샘플 로그에서 한 행을 구문 분석 할 수 있습니다. Hadoop Resource Manager ( https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html ) 로그 를 구문 분석 하려면 값을 org 로 설정해야합니다. .apache.hadoop.resourceestimator.translator.impl.RmSingleLineParser . 단일 라인 구문 분석기를 구현하여 사용자 정의 된 로그 파일을 구문 분석하려면 적절하게이 값을 변경해야합니다.
- resourceestimator.solver.provider
해석 프로그램 제공 업체의 클래스 이름입니다. 기본값은 org.apache.hadoop.resourceestimator.solver.impl.LpSolver 이며, 선형 예측 모델을 사용하여 예측을합니다. 사용자가 자체 모델을 구현하려는 경우 이에 따라이 값을 변경해야합니다.
- resourceestimator.service-port
ResourceEstimatorService가 수신 대기하는 포트입니다. 기본값은 9998입니다.
향후 과제
-
SkylineStore의 경우 영구 저장소 구현을 제공 할 계획입니다. 우리는 HBase가 미래의 규모 요구 사항을 입증 할 수 있도록 고려 중입니다.
-
Translator 모듈의 경우 Timeline Service v2를 기본 소스로 지원하기를 원합니다. 안정적인 API를 사용하고 로그가 비정상적이기 때문입니다.
-
작업 자원 요구 사항은 왜곡, 경합, 입력 데이터 또는 코드 변경 등으로 인해 실행에 따라 다를 수 있습니다. 런타임시 작업 진행률을 동적으로 모니터링하고 진행 상황이 예상보다 느린 경우 성능 병목 현상을 식별하는 Reprovisioner 모듈을 설계하고자합니다. ReservationUpdateRequest를 사용하여 작업의 자원 할당을 동적으로 조정합니다.
-
Estimator가 작업의 리소스 요구 사항을 예측할 때 예상 오류 (초과 할당 및 미달 할당의 조합) 등에 따라 예측과 관련된 신뢰 수준을 제공하고자합니다.
-
Estimator 모듈의 경우 강화 학습과 같은 기계 학습 도구를 통합하여 더 나은 예측을 할 수 있습니다. PerfOrator와 같은 도메인 별 솔루션과 통합하여 예측 품질을 향상시킬 수도 있습니다.
-
Estimator 모듈의 경우 새 로그를 기반으로 작업의 리소스 요구 사항을 증분 업데이트 할 수있는 증분 솔버를 설계하려고합니다.
구글 번역을 기반으로 매우 어색한 부분만 별도로 수정했습니다.
http://hadoop.apache.org/docs/current/hadoop-resourceestimator/ResourceEstimator.html
Apache Hadoop Resource Estimator Service – Resource Estimator Service
'IT > Etc' 카테고리의 다른 글
| 협업과 소통 그리고 자산화 (0) | 2020.03.03 |
|---|---|
| 업무분장 > 업무흐름 > 규정(절차서) (0) | 2020.03.03 |
| 맥북에서 크롬캐스트2 사용하기 (0) | 2017.05.07 |
| Maven 관련 오류 (0) | 2016.05.24 |
| CentOS에 Maven 설치하기 (0) | 2015.07.28 |


댓글