출처: 최상운의 사선(死線)에서 (1회) : 업무가 정확히 담긴 데이터 모델을 위한 시작 – DATA ON-AIR (dataonair.or.kr)
목차:
▷ 1회: 업무가 정확히 담긴 데이터 모델을 위한 시작
▷ 2회: 현행 모델 분석 1 : DB 스키마 기반의 리버스 ERD 작성
▷ 3회: 현행 모델 분석 2 : 리버스 ERD를 이용한 엔터티, 식별자 분석
▷ 4회: 현행 모델 분석 3: 리버스 ERD를 이용한 관계, 속성 분석
▷ 5회: 현행 모델 개선방향과 TO-BE 모델링 방향성 수립
▷ 6회: 데이터 모델링에 들어가면서…데이터 모델이란
▷ 7회: 데이터 모델 요소: 주제영역
[필자 소개]
최상운은 2000년 중반부터 데이터 관련 직무를 수행하고 있다. 은행·보험·증권·신용카드사 프로젝트에서 데이터 아키텍트, 데이터 모델러, PMO(Project Management Officer)를 수행했고, ISP 컨설팅에 참여했다. 한국데이터산업진흥원(KDATA)에서 주최하는 ‘DA 설계 공모대전’에서 2018년에 대상을, 2016년에는 금상을 각각 수상했다. 복잡하고 어려운 모델이 아닌 ‘업무가 정확히 담겨 있고 모두가 이해할 수 있는 모델’을 만들기 위해 현장에서 땀 흘리고 있다.
현장에서 전하는 데이터 모델링 이야기
필자는 수년간 시스템 통합(SI) 프로젝트에서 데이터 아키텍터, 데이터 모델러, PMO, 컨설턴트로서 역할을 했다. 그때마다 ‘왜 저렇게 데이터 모델링을 하지 어떻게 하면 사람들이 데이터 모델 이론을 쉽게 익히고 베스트는 아니지만 모델에 업무를 표현하고 관련자에게 공유할 수 있도록 도와줄 수 있을까’를 놓고 고민했다.
정답은 아니지만 데이터 모델링 과정을 이해하고 각 과정에서 해야 할 것과 점검할 것을 자료 형태로 정리하면 도움이 될 것 같아 조금씩 정리하고 있었다. 어렵고 복잡한 데이터 모델 이론은 배제하고 개발자 입장에서 접근 가능한 데이터 모델 이론을 소개하고, 실제 베스트와 워스트 데이터 모델 사례를 소개함으로써 '제대로 된 상당한 수준의 모델'보다는 '업무가 정확히 담겨 있고 모두가 이해할 수 있는 모델'을 작성할 수 있도록 하고 싶다는 생각에 감히 도전하게 되었다.
필자는 SI 프로젝트 현장에서 데이터 모델러로서 생사가 갈리는 전쟁터, 그 사선(死線)을 넘나들고 있다. 어떻게 하면 이 사선을 넘어 목표 지점에 도달할 수 있을까 이 차원에서 다소 무겁지만 현장에서 겪는 문제점들을 먼저 알아보고, 나름대로 대책도 제시해 보고자 한다. 대책이 정답은 아니더라도, 모든 것을 해결할 수는 없더라도, 새롭고 획기적인 방법은 아니더라도 모델 다운 데이터 모델을 만들기 위한 방법을 생각했고 그것을 나누고자 이 글을 시작한다.
야근에 주말 근무까지
벌써 몇 주째 야근하고 있는지 모르겠다. 야근뿐 아니라 두 달째 주말 근무도 하고 있다. 프로젝트는 4개월 전에 킥오프했다. 지난달까지 분석 단계였고, 지금은 설계 단계다. 앞으로 3개월 뒤에는 개발 단계에 들어간다. 주위 개발팀들은 분석·설계 단계에는 야근을 하지 않는데, 우리 데이터 모델러들은 왜 이리 야근과 주말 근무를 자주 하는지…
프로젝트 킥오프와 동시에 개인당 400개 이상의 AS-IS 테이블을 할당 받았다. ERD는 10년 전 프로젝트 때 작성하고는 현행화가 돼 있지 않다. ERD는 엔티티간 관계를 표시한 것인데, 관계선은 띄엄띄엄 있고 대부분 엔티티는 관계선이 그려져 있지 않다. 식별자가 없는 엔티티도 상당 수 존재한다. 그나마 주요 업무 이외 업무는 10년 전에 작성한 ERD조차 없다.
10년 전 작성된 ERD로는 현행 분석을 할 수 없으니 고객에게 요청해 운영 DB에서 스키마 정보를 제공받았다. 그런데 프로젝트 초기에 고객사에서 제공한 대상 테이블 수보다 많은 테이블이 존재한다. 초기 제공된 테이블 목록과 운영 DB에서 조회한 테이블 목록을 비교해 보았다. 고객사에게 추가된 테이블들 중에서 어느 업무 테이블을 사용중인지 식별을 요청했다. 돌아온 답변은 ‘잘 모르겠다’였다.
잘 모를 수밖에 없는 사유는 다음처럼 많았다. △해당 업무를 담당한 지 몇 년밖에 되지 않았는데 이전 담당자로부터 그런 테이블에 대해 설명을 들은 것이 없다. △소스를 찾아보았는데 해당 테이블 사용 소스를 발견하지는 못했지만, 데이터가 계속 증가하고 있어 미사용 테이블로 확정 짓기가 어렵다. △백업·임시성 테이블이 확실하지만 괜히 미사용 테이블로 분류했다가 나중에 누군가 사용하는 것으로 확인되면 책임을 물을 수 있으니 TO-BE에도 그냥 그대로 있어야 한다.
고객사로부터 제공받은 운영 DB 스키마 중 테이블 코멘트에 테이블에 대한 한글명이나 설명이 없는 것이 대부분이다. 테이블명은 로마자 알파벳과 숫자의 조합으로 구성돼 있다. 해당 고객사 담당자에게 문의해 보아도 본인들이 자주 사용하는 테이블 이외에는 어떤 정보를 담고 있고, 어떻게 사용되는지 알지 못 한다고 한다. 결국 데이터 모델러들에게 주어진 자료는 뜻 모를 알파벳과 숫자일 뿐이다.
운영 DB 스키마에서 FK(Foreign Key Constraint, 이하 FK로 통일)를 추출했는데 예상대로 FK 정보가 없다. 예상은 했지만 그나마 10년 전에 ERD에 표현했던 FK마저 실제 운영 DB에는 생성하지 않았다. 운영 중 데이터 삭제·변경 시 처리가 까다롭고 번거롭고, FK를 생성하면 쿼리 속도가 느려진다는 속설 때문에 대부분 DB에 FK를 생성하지 않는다. FK 정보마저 없으니 엔티티와 엔티티 간, 즉 데이터 간 관련성을 어떻게 분석해야 할지 막막 해진다.
이전 프로젝트를 하면서 메타 데이터 시스템(Meta Data System, 이하 메타)이 도입됐다. 운영 DB 스키마에서 추출한 컬럼명과 메타에 등록된 표준용어의 영문 약어를 비교해 컬럼명에 대한 표준용어 및 정의를 조회해 보았다. 그런데 표준용어에 대한 정의(Definition, 설명)의 용어명과 똑같다. 글자 하나 다르지 않고 똑같다. 엔티티를 구성하는 속성들의 용도와 정의를 파악하면 엔티티의 정체를 파악할 수 있다. 하지만 용어명과 똑같은 정의로 어떻게 엔티티 정체를 파악할 수 있겠는가 다시 한번 막막해지는 순간이다.
속성을 분석하기 위해 메타에서 표준용어를 검색하다가 이음동의(異音同意, 음은 다르나 뜻의 같은 것)나 동음이의(同音異義, 음은 같으나 뜻이 다른 것)에 대한 구분이 돼 있지 않음을 발견했다. 심지어 동음이의 용어에 대한 영문명 오류가 있는 것도 상당수 존재한다. 예를 들어 ‘수신금액’ 표준용어에서 ‘수신’(受信)은 Deposit, 즉 ‘금융 기관이 거래 관계에 있는 다른 금융 기관이나 고객으로부터 받는 신용’을 의미한다. 하지만 ‘수신’ 단어에 대한 영어 단어가 ‘Receive’로 돼 있고 영문 약어는 ‘RCV’로 돼 있다. ‘수신금액’ 영문 컬럼명은 ‘RCV_AMT’로 원래의 의미와 전혀 다른 뜻으로 돼 있다.
위 이야기는 필자가 이름만 대면 알 수 있는 대형 은행·보험·증권·신용카드사 SI 프로젝트에서 데이터 모델링을 수행하면서 겪었던 일반적인 이야기다.
10년이면 강산이 변한다고 했는데, 그동안 SI 프로젝트 현장의 상황은 그리 많이 바뀌지 않았다. 어디서부터 무엇이 잘못된 것일까 그 이유를 개인적으로 분석해 보면 아래와 같다.
1. 데이터에 대한 인식 및 투자의 제자리 걸음
2000년대 초반 국내 대형 SI사가 EA(Enterprise Architecture)를 SI 프로젝트에 적용하면서 BA(Business Architecture), TA(Technical Architecture), AA(Application architecture)와 더불어 DA(Data Architecture)가 많은 관심을 받게 됐다.
데이터를 기업의 핵심 자산으로 인식하고 데이터를 관리·통제하기 위한 관리체계(조직, 기능, 프로세스 등)가 제시됐다. 데이터 관리체계 구축은 많은 시간과 전사 차원의 노력이 필요하고, 구축 이후에도 지속적인 관리와 투자가 따라야 한다. 그러나 SI 프로젝트 종료 후 DA를 전담하는 기업 인력과 조직의 역량이 부족했고, 단기간의 성과를 중시하다 보니 어렵게 마련된 여전히 데이터를 기업의 핵심 자산이 아닌 비즈니스를 수행하면서 발생하는 것 또는 비즈니스를 지원하는 도구로 생각한다. 단기 이익과 경영진이 관심 있어 하는 ADW(Analytics Data Warehouse), RDW(Realtime Data Warehouse), OLAP 등 BI(Business Intelligence)에 대한 투자는 지속적으로 이뤄지는 모습이다. 하지만 원천 데이터를 관리하는 투자는 제자리걸음이다. 빅데이터로 대표되는 비정형 데이터를 활용한 마케팅에는 관심과 투자를 하지만 정작 비즈니스의 중심인 정형 데이터에 대한 관심과 투자는 제자리걸음이다.
기업은 늘어나는 데이터의 유일성, 정합성, 무결성을 유지하기 위한 데이터 저장 구조의 고도화 및 전문 인력에 대한 투자보다는 성능 좋은 하드웨어로 대체하는 방법을 택한다. 이는 근본적인 해결책이 아닌 임시방편일 수 있다.
2. 전문 데이터 관리인력 부족
필자가 데이터 모델러로서 일을 시작한 2000년도 중반만 하더라도 대형 SI 프로젝트에서는 개발팀과는 별도로 데이터 모델링 팀이 구성됐다. 전문 데이터 모델러가 데이터 현황을 분석해 문제점과 개선점을 도출해 TO-BE 데이터 표준화, 데이터 모델 표준 및 데이터 아키텍처 방향성을 수립했다. 또한 업무 데이터 모델링을 전문 데이터 모델러가 직접 수행했다.
그런데 몇 년 전부터는 대형 SI 프로젝트에 투입돼도 데이터 모델링을 직접 수행한 경우보다는 개발팀에서 개발자가 데이터 모델링을 수행하고 전문 데이터 모델러는 가이드(Guide)와 개발자가 작성한 데이터 모델을 점검(Inspection)만 하는 경우가 많았다.
이런 현상은 최근 몇 년간 SI 수행사들이 적정 금액보다 낮은 금액으로 프로젝트를 수주하는 데서 기인한다. SI 수행사는 적정 금액보다 낮은 금액으로 프로젝트를 수행해야 하기 때문에 기간과 투입 인력을 줄이고, 변경을 최소화해야 적자 없이 끝낼 수 있다.
하드웨어와 사무실 임대료 등의 비용을 줄이는 데는 한계가 있으므로 인건비를 줄일 수밖에 없다. 인건비를 줄이기 위해 전문 데이터 모델러 수십 명이 직접 데이터 모델링을 수행하기보다는 개발자가 데이터 모델링을 수행하고 소수 전문 데이터 모델러가 가이드와 모델 점검을 하는 방법으로 인건비를 줄이려 한다.
그러나 이는 데이터 모델링에 대한 무지에서 비롯된 잘못된 방법이다. 물론 개발자 중에는 데이터 모델링 실력을 갖춘 개발자도 있다. 하지만 전문 데이터 모델러의 데이터를 바라보는 관점과 개발자가 데이터를 바라보는 관점에 차이가 크다. 전문 데이터 모델러는 전사 관점에서 데이터를 바라보고 데이터의 유일성, 무결성, 정합성 및 유연성이 보장될 수 있도록 모델을 작성한다.
반면 개발자는 해당 업무에서 사용하는 데이터만 바라보기 때문에 업무 간 데이터가 중복되기도 한다. 중복된 데이터의 정합성과 무결성을 애플리케이션으로 맞추는 것이 어려워서 시간이 지나면 데이터의 정합성과 무결성이 깨지게 된다. 단지 인건비를 줄이기 위해 비전문 인력이 데이터 모델링을 수행하도록 하는 것은 기업의 핵심 자산으로서 데이터의 품질을 떨어뜨리는 결과를 낳게 된다.
3. 데이터 관리 시스템 및 체계 관리의 미흡
SI 프로젝트가 끝나면 기업 조직 내에 DA(Data Architecture)팀을 구성해 SI 프로젝트 과정에서 구축된 데이터 관리 시스템(메타 데이터 시스템, 데이터 모델 리포지터리, ETL 툴 등)를 관리하고 데이터 관리체계(데이터 표준, 데이터 모델, 데이터 흐름·배포, 데이터 거버넌스 등)를 통제하는 역할을 맡게 된다.
일반적으로 DB 관리를 맡고 있던 사원이 DA팀에 배치돼 SI 프로젝트 기간에 외부 전문가로부터 데이터 관리 시스템과 데이터 관리 체계에 대해 교육받고 실습을 한다. 1~2년의 SI 프로젝트 기간에 소수 몇 사람이 다양한 분야의 지식을 완벽하게 습득할 수는 없다. 지속적인 교육을 받아야 하고 필요하다면 해당 분야 전문가를 새로 고용해 SI 프로젝트 기간 중에 구축된 시스템과 체계를 유지하고 관리해야 한다.
하지만 현실은 업무량에 비해 DA팀 인원이 부족하고, 필요 지식을 갖추지 못한 상태에서 업무를 진행하다 보니 잘못된 처리를 하는 경우가 많다. 또 정책을 마련하고 이를 통제하기 위해서는 조직 내에서 영향력이 있어야 하는데, 대부분 기업에서 DA팀은 영향력을 갖고 있지 못한 거 같다. 이러다 보니 어렵게 구축된 정책과 표준이 흔들리게 되고, 하나둘 예외를 인정하다 보니 너무 많은 예외로 인해 표준이 모호하게 돼 버린다.
절차와 통제를 무시하게 돼 데이터 관리 시스템이 무용지물이 되는 경우도 많다. 예를 들면, 데이터 모델링의 경우 아래와 같은 절차와 통제를 받게 된다.
① 개발팀에서 ERD에 신규 엔티티를 추가하거나 기존 엔티티를 수정한다.
② 신규 속성이 있다면 메타에 신규 용어를 신청한다.
③ 신규 용어를 표준 담당자에게 승인받는다.
④ 신규 또는 수정된 엔티티가 포함된 ERD를 모델 리포지터리(ERwin 모델마트 또는 DA# Repository 등)에 등록한다.
⑤ 메타에 신규 또는 수정된 엔티티를 모델 리포지터리에서 불러내어 신규 또는 수정 요청한다.
⑥ 신규 또는 수정 요청한 엔티티를 데이터 모델 담당자에게 승인받는다.
⑦ 메타에 승인받은 엔티티에 대한 테이블 생성을 요청한다.
⑧ DBA는 메타에서 테이블 생성 요청 건을 기준으로 물리적 오류가 없는지 확인하고 문제가 없으면 DB에 테이블을 생성·수정한다.
간략하게 적어 보았지만 테이블 하나를 신규 작성 또는 수정하더라도 여러 단계를 거쳐야 하고 단계마다 담당자의 승인을 받아야 한다.
개발 일정이 빠듯한데 단계별로 문제없이 통과돼도 최소 2일이 소요된다. 이때 한 단계에서 반려라도 되면 그 만큼 개발 일정이 지연된다. 개발이 내일 까진데 정상적인 절차를 밝으면 일정에 맞춰 개발을 할 수 없어 팀장님 ‘빽으로’ 나중에 정식 절차를 밝을 거라고 하고 우선 DB에 테이블을 생성해 개발을 마친다.
하지만 개발 요청이 계속 들어와 ERD 반영을 차일피일 미루다 보면 잊게 되고, 이런 일이 반복되면 ERD는 현행화가 안 되고, 메타는 테이블에 대한 상세정보가 없고 DB와 형상이 맞지 않아 메타로서의 기능을 하지 못 하게 된다. DB에는 단순히 스키마 정보만 있으므로 테이블이 어떤 정보를 관리하고, 업무적으로 어떻게 처리되는지에 대한 설명이 없어 담당자가 바뀌면 프로그램 소스를 분석해야만 알 수 있게 된다.
‘제대로 된 상당한 수준의 모델’을 만들려면 데이터 모델러는 상당 기간의 학습을 통해 이론적 지식을 갖추어야 하고, 실전에서 모델링 경력을 쌓아야 하고, 해당 업무에 대한 지식이 있어야 하며, 관련자들을 리딩 할 수 있는 커뮤니케이션 스킬을 갖추어야 한다.
하지만 우리가 일하고 있는 현장에서는 ‘제대로 된 상당한 수준의 모델’보다는 ‘업무가 정확히 담겨 있고 모두가 이해할 수 있는 모델’이 필요하다. 꼭 데이터 모델 전문가가 아니더라도, 전문 지식이 없더라도 프로젝트 단계(분석·설계·개발·통합 테스트·이행)와 각 단계에서 습득해야 하는 지식, 해야 할 일, 점검 사항을 알면 최소한 프로젝트를 해본 사람이라면 ‘업무가 정확히 담겨 있고 모두가 이해할 수 있는 모델’을 작성할 수 있다고 생각한다.
아래 그림은 프로젝트 기관 동안 데이터 모델링 단계와 각 단계에서 해야 할 것을 정리한 것이다.

그림. 데이터 모델링 단계와 해야 할 일
‘현행분석’부터 하나씩 풀어내기
데이터 모델링 단계별로 무엇을 어떻게 해야 하며, 어떤 것을 점검해야 하며, 이를 위해 갖추어야 할 필요 지식이 무엇인지 하나씩 살펴보겠다. 먼저 ‘현행분석’을 주제로 찾아간다. 갓 프로젝트에 투입되면 수집해야 하는 자료와 어떻게 이 자료로 AS-IS 모델을 도출·분석해 문제점을 발견하고 TO-BE 방향성을 도출할 것인지, 이 과정에서 범하기 쉬운 실수를 알아보고, 도움이 될 만한 팁을 소개하고자 한다.
프로젝트 투입 첫날이다. 원래는 2주 전에 시작했어야 하는 프로젝트가 고객사와 수행사 간 기술 협상이 늦어 지면서 2주 늦게 시작했다. 2주 늦게 시작했지만 프로젝트 오픈 일자는 변동이 없다. 이 말은 기술협상으로 지연된 2주를 어떻게 하든 공정을 앞당겨 2주만큼의 시간을 보충해야 한다는 것이다.
함께 일할 사람이 누구인지 확인한다
첫날이라서 그런지 어수선하다. 자리는 배정됐지만 IP 할당이 아직 안 된 자리도 있어 기본적인 PC 세팅조차 하지 못 하는 사람들도 있다.
PC 세팅을 완료한 후 우선 프로젝트 조직도를 찾아보았다. 프로젝트 조직도에는 조직체계와 업무별 고객사와 수행사 담당자가 명시돼 있어, 내가 어떻 사람과 함께 일해야 하는지 확인할 수 있다. 파일서버 여기 저기를 뒤져 드디어 제안서에 포함된 조직도를 찾을 수 있었다. 그런데 조직체계는 어느정도 나와 있었지만 내가 맡은 데이터 모델링팀의 고객사 담당자가 아직 TBD(To Be Defined, 문서 작성 시점에는 확정할 수 없어 나중에 확정한다’는 의미) 상태다. 데이터 모델링팀뿐 아니라 각 업무팀의 고객사 및 수행사 TL(Team Leader) 상당 수도 TBD로 돼 있어서 내가 어떤 사람과 함께 일해야 할지도 알 수 없다. 프로젝트 사업관리팀에 문의해 보니 2주 후에나 완성된 조직도가 나온다고 한다. 그럼 2주 동안 그냥 앉아 있어야 할까
프로젝트가 시작되면 기술지원 관련 팀(인프라팀, 아키텍처팀, 표준화팀, 데이터 모델링팀 등)은 바쁘다. 개발하기 위해서는 애플리케이션 서버, DB 서버, MCI(Multi Channel Interface) 서버, 프레임워크 서버 등이 준비돼 있어야 한다. 코딩하기 위한 소프트웨어 환경이 만들어져 있어야 하고, 각종 개발 표준이 개발 전에 마련돼 있어야 한다. 그래서 기술지원팀은 프로젝트 시작과 함께 야근과 주말 근무가 많다.
조직도가 완성되기를 기다릴 시간이 없다. 이때 정신을 차리지 않으면 금쪽같은 2주가 금방 흘러가게 될 판이다. 우선 수행사 프로젝트 매니저(PL)를 통해 업무별로 모델 담당자와 연락처를 조사해 달라고 회신을 돌렸다. 이번 주까지 고객사 모델 담당자를 확정해 달라고 고객사 PM을 통해 공식 요청했다.

[그림 1] 업무별 고객사·수행사 담당자 확인 양식
세상일이 다 그렇지만 나 혼자 할 수 있은 건 그리 많지 않다. 특히 최대 300~400명이 동시에 일을 하는 대형 SI 프로젝트에서 이해 당사자간의 협업이 필수적이다.
데이터 모델은 나 혼자 하루 종일 컴퓨터 앞에 있다고 해서 작성할 수 있는 것이 아니다. 프로젝트 초기에 업무(비즈니스)와 업무에서 다루는 데이터를 가장 많이 아는 사람은 고객사 담당자다. 그리고 내가 작성한 모델을 가장 많이 보고 활용하는 사람은 업무팀 개발자다. 모든 스트레스는 인간관계에서 비롯된다고 하여 웬만하면 새로운 인간관계를 맺기를 꺼리는 요즘이지만, 프로젝트 초반에 나와 함께 일할 사람을 파악하고 프로젝트 기간 동안 이들을 친구로 만들면 ‘베스트’다. 베스트에 이르지 못하더라도 최소한 원수 사이가 되지 않도록 서로 존중하며 협업할 수 있어야 한다.
언제 어떤 일을 해야 할지를 계획한다
WBS(Work Breakdown Structure)는 말 그대로 일을 쪼개 놓은 구조로서 일종의 해야 할 일의 리스트다. WBS에는 어떤 일(Activity와 Task)을 언제부터 언제까지 누가 할 것이며 이때 필요한 자원(장비, 사무실 등)이 무엇인지 기술돼 있다. 각 일(Task)간 선후행 관계가 나와 있다. 또 각 일(Task)이 종료되면 어떤 결과물이 나와야 하는지 기술돼 있다.
프로젝트 관리(Project Management) 관점에 측정할 수 없는 것은 관리할 수 없으므로 프로젝트의 모든 일은 측정 가능해야 한다. 일의 시작이 있으면 끝이 있어야 한다. 그 기간이 길면 관리와 측정이 어려워지므로 최대 2주를 넘지 않도록 일정을 계획한다. 짧게는 1년 길게는 2~3년이 걸리는 SI 프로젝트에서 계획을 세우는 것은 매우 중요 하다.

[그림 2] WBS의 예
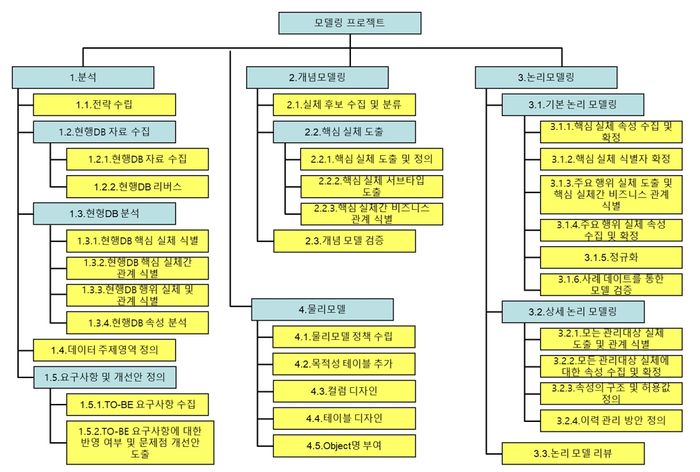
[그림 3] 데이터 모델링 단계와 해야 할 일
데이터 모델링의 경우 일반적으로 [그림 3]과 같이 주요 태스크들이 있으므로 각 태스크의 일정을 잡으면 된다. 하지만 WBS에서 개발팀의 분석·설계·개발 일정과 다르면 문제가 되므로 개발팀의 일정 확인은 필수적이다. 업무별로 분석·설계·개발 일정이 동일한 프로젝트가 있고, 업무별로 일정이 제각각인 프로젝트가 있다. 여기서 점검할 포인트는 내가 맡은 업무의 데이터 모델링 일음주직 현행 분석중이거나, 나는 야근과 주말 작업을 해서 논리모델까지 끝냈는데 개발팀은 아직 인력조차 투입되지 않았다면 그 간격으로 인한 손실이 크다. 따라서 내가 맡은 업무 개발팀의 WBS를 확인해 개발팀 일정에 맞춰 데이터 모델링 일정을 수립해야 한다.
AS-IS 자료를 수집한다
우여곡절 끝에 고객사 담당자와 개발팀 담당자 명단을 확보했다. 오전에 첫 미팅을 진행 했다. 우선 고객사 담당자에게 ERD가 있어서 현행화 수준에 대해 문의했다. 돌아온 답변은 ‘ERD는 10년 전 프로젝트 때 작성된 것뿐이고 이를 현행화하지 않았다’였다. 다소 실망스러웠지만 대부분 프로젝트에서 겪었던 바라 차근차근 AS-IS 자료를 수집하기로 했다.
데이터 모델링 이론서들을 보면, 현업에서 사용하는 각종 양식 및 보고서, 시스템 관리 문서(운영 매뉴얼 등), 현업 사용자와의 인터뷰, 관련 서적, 데이터 흐름도(DFD, Data Flow Diagram), 전산 화면 등으로부터 엔티티와 속성을 도출할 수 있다고 나와 있다. 맞는 말이다. 하지만 SI 프로젝트에서 이런 자료들을 수집하고 분석할 시간이 넉넉하지 않고 효율적이지도 않다. 신규 사업 프로젝트를 진행하지 않는 이상, 대부분은 현재 운영하고 있는 전산시스템이 존재한다. 모델이 잘되고 안 되고를 떠나 현재 운영중인 전산 시스템만큼 확실한 AS-IS 자료는 없다. 고객사 담당자에게 현재 운영 DB에서 스키마 정보를 추출해 달라고 요청했다.
쿼리만 돌리면 간단히 얻을 수 있어 오후에 스키마 정보를 받았다. 메타 시스템에 등록된 테이블과 컬럼 정보와 비교해 최대한 테이블 한글명과 속성명을 엑셀 파일에 채워 넣었다. 그러지만 메타 시스템에 등록돼 있지 않는 테이블도 있고, 컬럼도 표준 용어를 사용하지 않는 것들도 있다. 메타 시스템에 등록된 테이블 정의는 테이블 한글명에 조사만 붙인 수준이었다. 해당 테이블이 어떤 데이터를 관리하고 어떻게 사용하는지 분석하기 힘들다. 사용하는 것인지 아닌지도 알 수 없는 테이블도 있다.

[그림 4] AS-IS 테이블 조사 양식
[그림 4]와 같이 AS-IS 테이블에 대한 테이블 한글명, 테이블 설명, 사용 여부, 고객사 담당자, 개발팀 담당자 항목을 채워 달라고 고객사에게 요청했다.
이 자료는 데이터 모델링 대상이 되는 AS-IS 테이블 목록으로 활용할 것이며, TO-BE 테이블과 매핑해 AS-IS 테이블이 TO-BE 데이터 모델에서 누락됐는지 여부와 정량적인 데이터 모델링 진척율을 측정하는 데 활용된다.
AS-IS 리버스 ERD를 작성한다
AS-IS 테이블 조사를 통해 데이터 모델링 대상 테이블이 식별됐다. 엑셀 파일은 대량 작업을 하는 데는 유용하지만 어떤 테이블이 있고, 테이블에는 어떤 컬럼이 있고, 컬럼의 데이터 타입 길이와 널(Null) 옵션 등을 한눈에 파악하기에는 불편하다. 특히 테이블 간에 관계를 전혀 파악할 수 없는 자료 형식이다. 데이터 모델러에게는 ERD(Entity Relationship Diagram)가 테이블이 관리하는 정보와 테이블 간 참조 관계 등을 파악하는 데 가장 친숙한 자료 형식이다.
데이터 모델링 프로그램 자체적으로 엑셀 자료를 ERD로 전환해 주는 기능을 이용하거나, 제3자가 플러그인 방식으로 별도 프로그램으로 ERD로 전환해 주는 기능을 이용해 AS-IS 리버스 ERD를 작성한다.

[그림 5] ERwin Add-In으로 ERD 리버스

[그림 6] DA#으로 ERD 리버스
AS-IS 리버스 ERD를 작성함에 있어 팁은 AS-IS 테이블 정보와 AS-IS 컬럼 정보를 ERD 안에 포함하는 것이다.
일반적으로 SI 프로젝트에서 중요한 20% 테이블이 1:N, N:1 또는 N:N으로 통합·분리·수정 등이 발생해 복잡한 매핑이 필요하다. 하지만 나머지 80% 테이블은 단순 컬럼 추가/삭제만 발생해 단순 1:1로 매핑된다. 따라서 AS-IS 테이블 정보와 컬럼 정보를 포함해 ERD를 작성하고, 이 ERD를 기반으로 TO-BE 모델링을 한다면 데이터 표준 적용으로 인한 엔티티·테이블명 변경이나 속성·컬럼명이 변경되더라도 AS-IS 정보 추적이 가능하다. 따라서 향후 데이터 이관(이행)을 위한 테이블 및 컬럼 매핑 정의서 산출물 작성 시 80% 테이블은 데이터 모델링 프로그램에서 제공하는 엑셀 포맷으로 변환기능을 이용해 쉽고 간편하고 빠르게 산출물을 작성할 수 있다.
AS-IS 정보는 엔티티 및 속성 UDP(User Defined Property)를 만들고 이 곳에 AS-IS 정보를 입력 하도록 한다. 또한 데이터 모델링 프로그램에 따라서는 엑셀 문서 양식을 이용해 일괄 입력할 수 있는 기능을 제공하기도 한다.

[그림 7] AS-IS 테이블 및 컬럼정보 포맷을 데이터 모델링 프로그램에 삽입한 예
리버스 ERD 분석
현행 DB 스키마 정보로부터 리버스 ERD를 작성했다.
리버스 ERD로 무엇을·어떻게 분석할 것인지에 대해 알아본다.
엔터티를 실체·주요·행위·목적으로 분류
금융권의 경우 한 모델에 300~400개 정도의 엔터티가 존재한다. 이 많은 엔터티를 4주 정도의 현행분석 기간 동안 ‘정석대로’ 분석하기는 힘들다.
‘파레토 법칙(Pareto principle)’을 들어보았는가 ‘80대20 법칙’이라고도 하는데 ‘전체 결과의 80%가 전체 원인의 20%에서 일어나는 현상'을 가리킨다. 이 법칙은 데이터 모델에도 적용된다. 전체의 20% 엔터티가 업무의 80%를 담당하고, 나머지 80% 엔터티는 참조나 부가적인 정보를 관리한다. 따라서 80% 업무를 담당하고 있는 20% 엔터티에 집중해야 한다.
하지만 많은 엔터티 중 어떤 것이 20% 안에 드는 것인지를 모르는데! 그래도 걱정할 필요는 없다. 프로젝트 초기 단계에는 현행 엔터티에 대해 가장 많이 알고 있는 사람은 고객사 담당자다. 고객사 담당자가 엔터티 명만 보고 바로 뭐라고 설명할 수 있는 엔터티가 바로 20%의 주인공이다.
‘AS-IS 테이블 조사 양식’에 '엔터티 분류' 항목을 추가하고 엔터티가 실체·주요·행위·목적 중 어느 것에 해당하는지를 고객사 담당자에게 요청한다.

[표 1] 엔터티 분류
다른 건 몰라도 실체와 주요 엔터티는 가장 많이 사용하고 있으므로 고객사 담당자가 자신 있게 분류해 줄 수 있을 것이다.

[그림 1] 실체·주요·행위·목적 순으로 엔터티 분석
수백 개의 엔터티를 한 번에 분석할 수는 없다. [그림 1]과 같이 실체·주요· 행위·목적 엔터티로 분류하는 이유는 중요도에 따른 분석 및 설계 우선 순위를 정하기 위해서다.
이 글의 앞에서 소개했듯이 20%로 80% 일을 할 수 있으니 얼마나 효율적인가!
엔터티 정체 파악
그 많은 엔터티 가운데 20%의 엔터티를 분류했다. 이제 엔터티 정체를 파악할 차례다. 엔터티가 어떤 데이터를 관리하는지를 확인하는 것이다. 다른 말로는 엔터티를 정의(Definition)하는 일이다.
너무 걱정할 필요는 없다. 이 과정은 20% 엔터티를 분류해준 고객사 담당자와 함께할 것이기 때문이다. 먼저 리버스 ERD를 보기 좋게 엔터티 명에 공통된 단어가 있는 것끼리 모아 놓고 좌우 정렬한다. 엔터티 명에 공통된 단어가 있으면 관련성이 있을 가능성이 높다. 다음으로 고객사 담당자와 인터뷰를 하여 엔터티 하나 하나를 보면서 어떤 데이터를 관리하는지, 업무적 특성은 있는지, 사용 빈도는 어떻게 되는지, 관련된 엔터티는 어떤 것인지를 물어보고 기록한다.
이때 유의할 점은 아래와 같다.
(1) 한 개 엔터티에 대해 많은 시간을 들이지 않는다
고객사 담당자가 술술 풀어 놓으면 그 만큼 중요한 엔터티란 뜻이다. 반대로 머뭇거리며 헷갈려 하면 덜 중요한 엔터티로 볼 수 있다.
지금은 전체적인 윤곽을 잡는 단계임으로 한 곳에 너무 많은 시간을 들이지 않도록 한다.
(2) 너무 깊게 들어가지 않는다
고객 담당자와 인터뷰는 어떤 데이터를 관리하고, 어느 정도 중요하고, 다른 엔터티와 관계가 있는 것을 대략적으로 파악하기 위한 목적이므로 너무 깊게 들어가지 않는다. 간혹 A부터 Z까지 설명하려는 열정이 넘치는 고객사 담당자를 만날 수도 있다. 현장에서 모델링을 하다 보면, 적절한 타이밍에 말을 끊는 지혜로운 기술()도 필요하다.
(3) 중요한 속성을 물어본다
중요한 속성이 무엇인지 물어보되 즉각적인 대답이 없으면 그냥 넘어간다. 고객사 담당자는 유지·보수를 하면서 자주 사용하는 속성은 한 번에 알아본다.
속성은 엔터티를 구성하는 요소다. 속성을 분석하면 엔터티 정체를 더 확실히 파악할 수 있다.
식별자 분석
식별자(Identifier)는 데이터를 유일하게 구분할 수 있는 한 개 속성 또는 여러 개의 속성 집합이다. 또한 엔터티를 대표하는 속성 또는 속성 집합이다.
식별자를 흔히 PK(Primary Key)라고 생각하는데 엄밀히 말하면 식별자와 PK는 유사 하지만 다르다. 하지만 여기서는 식별자와 PK를 같은 의미로 사용하겠다.
식별자를 이해하기 위해서는 함수 종속성(Functional Dependency)을 거론하지 않을 수 없다. 함수 종속성은 정규화를 이해하는 이론이기도 하다. 여기서는 간략하게 설명한다.
함수 종속성은 데이터들이 어떤 기준 값에 의해 종속되는 현상을 지칭하는 것이다. A가 B에 의해 결정된다면, B를 결정자(Determinant)라고 하고 A는 종속자(Dependent)라고 한다. 만일 모든 속성에 대한 결정자가 있다면 이를 식별자라고 한다. 즉 식별자를 찾는 것은 모든 속성의 결정자를 찾는 것이다.

[그림 2] 함수 종속성의 예시
[그림 2]에서 사원번호는 사원이름, 전화번호, 주소를 결정하는 결정자다. 만일 이 엔터티를 ‘사원’이라고 하면 ‘사원’ 엔터티의 식별자는 ‘사원번호’다. 식별자는 엔터티가 관리하는 데이터의 성격을 규정하고 엔터티를 대표하는 것이므로 정확한 식별자 도출은 좋은 데이터모델을 만드는 기본이자 핵심이다.
데이터 모델링 자료들을 보면 후보 식별자, 주 식별자, 인조 식별자, 대체 식별자 등 여러 종류의 식별자가 나와 혼란스러울 수 있다. 여기서 분류 기준에 따른 식별자의 종류를 간단하게 알아본다(식별자에 대한 자세한 소개는 이어질 연재에서 다루겠다).
(1) 대표성을 기준으로 식별자 분류
엔터티를 대표하는지 여부에 따른 식별자 분류다.
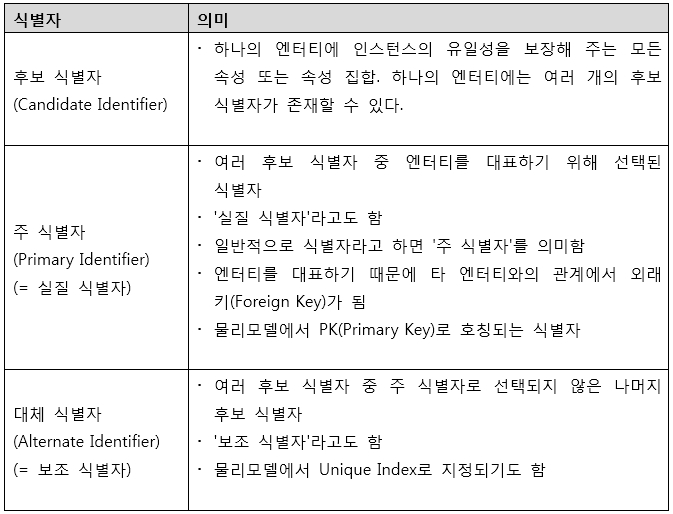
[표 2] 대표성을 기준으로 식별자 분류
(2) 대체 가능 여부를 기준으로 식별자 분류
엔터티에 원래 존재하는 속성으로 구성됐는지 여부에 따른 분류다.

[표 3] 대체 가능 여부를 기준으로 식별자 분류
(3) 속성 수 기준으로 분류
식별자를 구성하는 속성이 1개인지, 여러 개인지에 따른 분류다.

[표 4] 속성 수 기준으로 분류
식별자 분류에 따른 식별자 종류를 예제를 통해 확인해 보자.

[그림 3] 주문내역 엔터티 1
위 주문내역 엔터티는 다음과 같이 설명할 수 있다.
- 2개의 후보 식별자, 후보 식별자 ①과 후보 식별자 ②가 있다.
- 2개의 후보 식별자 중 후보 식별자 ①이 주 식별자로 선정돼 후보 식별자②는 대체 식별자가 됐다.
- 주 식별자는 본래 엔터티에 있는 속성으로 구성됐기 때문에 본질 식별자이다.
- 주 식별자는 여러 개의 속성으로 구성됐으므로 복합 식별자다.

[그림 4] 주문내역 엔터티 2
주문내역 엔터티의 식별자를
- ‘주문번호’로 변경했다. ‘주문번호’는 본래 엔터티에 있는 속성이 아닌, 인위적으로 생성한 속성이므로 인조 식별자를 주 식별자로 했다.
- 주 식별자는 한 개 속성으로 구성됐으므로 단일 식별자다.
- 주 식별자를 ‘주문번호’로 선정해 2개 후보 식별자는 대체 식별자가 됐다.
식별자는 데이터의 유일성을 보장하고, 데이터를 생성하는 기준이 돼야 한다. 따라서 유일성·최소성·안전성·활용성·비암호화·최소길이·고정길이 원칙에 부합한 것을 지정해야 한다.
그러나 안타깝게도 기존 모델의 식별자는 이러한 원칙에 따라 지정하지 않고 잘못 지정한 경우가 많다. 식별자를 잘 못 지정한 몇 가지 사례를 알아본다.
(1) 검색조건 사용을 이유로 식별자에 포함하는 경우
현장에서 가장 많이 발견되는 경우다. 데이터의 유일성을 보장하는 데 관여하지 않는 속성이나 검색조건에 많이 사용되는 속성을 식별자에 포함시키는 것이다. 별도 인덱스를 생성하지 않고 PK 인덱스에 포함시키는 형태다.

[그림 5] 고객기본 엔터티
‘고객기본’ 엔터티의 식별자는 ‘고객번호’다. 그런데 검색조건에 ‘고객명’이 많이 사용되기 때문에 식별자로서의 자격이 없는 ‘고객명’을 식별자에 포함한 사례다. 하지만 ‘고객명’을 식별자에 포함해 PK 인덱스를 생성하더라도 복합 인덱스의 첫 번째 컬럼이 ‘고객번호’이므로 검색조건에 고객명만 입력한다고 인덱스를 탈 수 없다.

[그림 6] 계좌거래내역 엔터티
이 엔터티의 본질 식별자는 ‘계좌번호+거래일시(연월일+시분초)’다. 원래 존재하는 속성은 아니나 관리적인 측면에서 계좌번호에 종속적으로 증가하는 일련번호인 ‘거래일련번호’를 추가해 ‘계좌번호+거래일련번호’를 주 식별자로 했다.
‘거래구분코드’는 해당 거래가 어떤 거래(입금·출금·취소 등)인지를 구분하는 것이다. 이는 데이터의 성격을 나타내는 것이지 데이터의 유일성을 보장하는 데 참여하는 속성은 아니다. 하지만 계좌번호별 ‘입금’ 거래를 조회하는 검색조건으로 많이 사용된다는 이유로 식별자에 포함한 사례다.
이것을 PK 인덱스로 생성한다면 복합 인덱스의 첫 번째 컬럼이 ‘계좌번호’이므로 인덱스를 탈 수도 있겠지만 ‘거래구분코드’는 세 번째 컬럼이므로 결국 인덱스를 효율적으로 사용하지 못하게 된다. 또한 불필요한 컬럼을 인덱스로 만들어 인덱스 사이즈를 증가시켜 결국 시스템 성능에 좋지 않은 영향을 미친다.
(2) 데이터가 변경되는 속성을 사용한 경우
상위 엔터티 식별자 값을 업데이트하면 식별자를 상속받는 하위 엔터티 값 역시 업데이트해야 참조무결성을 지킬 수 있다. 만일 상위 엔터티 식별자 값을 변경했는데 상위 엔터티의 식별자를 참조 키로 갖고 있는 모든 하위 엔터티 참조 키 값을 같이, 그것도 동시에 업데이트하지 않으면 참조무결성이 깨지게 된다. 더불어 조인 시 엉뚱한 결과가 조회된다. 메타시스템으로 참조 관계가 관리되고 있더라도 동시에 참조 키 값을 업데이트하는 것은 현실적으로 불가능하다.

[그림 7] 결재 프로세스 ERD
‘결재진행내역’ 엔터티의 정확한 식별자는 ‘결재번호’다. 그런데 ‘결재진행상태코드’가 검색조건에 많이 사용된다는 이유로 식별자에 포함했다. ‘결재진행상태코드’는 결재가 진행됨에 따라 그 값(상신·취소·대기·검토·승인·반려·삭제)이 업데이트되는 속성이다.
[그림 7] ERD와 같이 상위 엔터티인 ‘결재진‘결재항목별내역’ 엔터티의 ‘결재진생상태코드’도 업데이트돼야 한다. 만일 제때 업데이트되지 않으면 조인 시 엉뚱한 결과가 조회될 것이다. 정상적으로 ‘결재진행내역’ 엔터티의 ‘결재진행상태코드’를 일반속성으로 했다면, 값이 업데이트돼도 하위 엔터티에는 전혀 영향이 없다.
따라서 식별자는 그 값이 변경되지 않는 속성을 선정해야 한다. 만일 적절한 속성이 없는 경우 인조 식별자(본질 속성+인조 속성으로 구성)를 도입하고 변경되는 속성은 일반속성으로 해야 한다.
(3) 암호화한 속성을 사용한 경우
개인정보 보호 강화에 따라 기업 또는 기관에서는 개인정보 보호조치를 해야 한다. 이 중 DB 암호화는 관리적·기술적 보호 조치의 빈 틈을 이용해 데이터를 반출하더라도 개인정보가 노출되지 않는 최종적이며 강력한 조치다.
문제는 DB 암호화 시 적용하는 암호화 방식과 키 관리 방식에 따라 원천 값과 암호화 후 값이 다르다는 점이다.

[그림 8] 암호화한 속성 사용
[그림 8] ERD에서 ‘개인관계자기본’ 엔터티에서 ‘관계자주민등록번호’가 식별자다.
평문(plain text) 주민등록번호를 암호화 알고리즘과 암호화 키로 암호화하면 값이 달라진다. 기간별 또는 시스템간 암호화 키를 다르게 사용했다면, 동일 평문에 대한 암호화한 값이 다르므로 암호화한 값으로 조인하는 것은 무의미하다.
암호화한 값을 복호화(decoding)해 조인하는 방법이 있다. 하지만 이때는 인덱스를 탈 수 없다. 온라인성 단건 조회가 아닌, 배치성의 다량 조회일 때는 모든 데이터를 복호화해야 하므로 결과 출력 시간이 크게 늘어 난다(타임 크리티컬이 강조되는 배치 처리일 때 시간 내 처리가 되지 않을 수 있어서 업무 개시시간을 보장하지 못할 수도 있다).따라서 암호화 대상이 되는 속성이 포함되지 않은 후보 식별자를 주 식별자로 하거나 적절한 후보 식별자가 없을 경우 인조 식별자를 사용한다.

[그림 9] 인조 식별자로 암호화 조인문제에 대처
[그림 9]처럼 ‘관계자주민등록번호’ 대신 인조 식별자인 ‘개인관계자번호’로 대체해 암호화로 인한 조인 오류와 성능 저하에 대비한다.
(4) 길이가 일정하지 않거나 긴 속성 사용 시
물리모델은 DB의 물리적 특성과 성능을 고려해해야 하므로 주 식별자 속성 값이 짧고, 고정 길이여야 효율적이다(주 식별자는 PK 인덱스로 생성되고 디스크에 저장되는 공간이 적을수록 디스크 I/O를 줄일 수 있다. 데이터 1건은 몇 바이트 차이밖에 나지 않지만, 전체를 보면 무시하지 못 할 성능 차이가 발생할 수 있다).

[그림 10] 데이터 타입 길이가 가변적인 ERD
[그림 10] ERD는 ‘이벤트내역’ 엔터티의 식별자가 ‘이벤트명’으로 돼 있고, 데이터 타입 길이가 가변 문자열 200바이트로 돼 있다. 이벤트 명을 유일하게 부여할 수 있는 한계가 있고, 값이 길고 길이도 일정하지 않다. 이에 따라 하위 엔터티나 참조 키를 갖고 있는 엔터티 간 조인 시 효율적이지 못 하다. 이런 경우 인조 식별자인 ‘이벤트번호’로 대체하면 값이 짧아져 조인 시 더 효율적이다.

[그림 11] 인조 식별자로 대체
일반적으로 ~명, ~내역, ~금액, ~료 등의 속성은 될 수 있으면 주 식별자에 포함하지 않는 것이 좋다.

[그림 12] 금액 속성을 식별자로 한 ERD
[그림 12] 엔터티는 금액 구간별로 담보등급을 관리하는 엔터티다. 시작과 종료 금액을 식별자로 한 것이 타당성이 없는 것은 아니다. 하지만 시작 금액과 종료 금액을 식별자로 하더라도 기본키 제약조건(Primary Key Constraint)으로 데이터 입력 시 금액 구간의 중첩을 막을 수는 없다.

[그림 13] 금액 구간 중첩 데이터 입력 예시
어차피 금액 구간의 중첩을 막으려면 별도의 로직을 애플리케이션에서 구현해야 한다. 따라서 시작과 종료 금액을 식별자가 아닌, 일반 속성으로 하더라도 금액 구간별 담보등급을 구하는 데 문제가 없다. 오히려 ‘담보등급코드’를 식별자로 하는 것이 저장 공간 및 참조 키 역할을 하는 데 더 효과적이다.

[그림 14] ‘담보등급코드’를 식별자로 지정
(5) 식별자가 동일한 엔터티가 여러 개일 때
현행 모델 분석 과정에서 식별자가 동일한 엔터티가 여러 개 있는 경우를 종종 보게 된다. 식별자는 가게의 간판과 같은 역할을 한다. 한 건물에 동일한 간판을 내세운 가게가 많다면 어떻게 될까 엔터티 명을 전사적으로 유일하게 부여(예: ‘업무명_엔터티 명칭’으로 부여)하면 엔터티를 식별할 수 있듯이, 식별자도 전사적으로 유일하게 부여하는 것이 이상적이다. 현실적으로 전사적으로 유일하게 부여하는 게 어렵다면, 최소한 한 모델 안에서는 유일하게 부여하도록 한다.

[그림 15] 식별자가 동일해 엔터티 파악이 어렵고 모델의 가독성 저하
식별자를 유일하게 부여하는 방법 중 하나는 적절한 수식어를 붙여 상세하게 하는 것이다. 예를 들어 도메인은 '계좌번호'를 사용하지만 '여신계좌번호', '수신계좌번호', '외환계좌번호'와 같이 수식어를 붙이면 데이터의 성격을 직관적으로 알 수 있다.
또 '계좌번호+일련번호'도 엔터티 정의에 따라 '여신계좌번호+여신거래일련번호', ‘여신계좌번호+여신상환일련번호', '수신계좌번호+수신입금일련번호' 등으로 적절한 수식어를 붙여 상세하게 하면 유일하게 부여할 수 있다. 이렇게 하면 엔터티가 어떤 데이터를 관리하는지 직관적으로 알 수 있어 모델의 가독성을 높일 수 있다.식별자가 유일하면 참조 키를 보고도 어떤 엔터티와 관계가 있는지도 직관적으로 알 수 있다.

[그림 16] 적절한 수식어로 유일한 식별자를 부여해 엔터티 파악과 모델의 가독성 제고
현장에서 흔히 볼 수 있는 식별자를 잘 못 설정한 사례를 살펴보았다. 이 상황을 염두에 두면 현행 ERD나 리버스 ERD에서 설정한 식별자의 적절성 여부를 분석할 수 있을 것이다.
리버스 ERD에서 엔터티 간 관계를 어떻게 분석하고, 속성을 어떻게 분석 하는지 알아보겠다.
ERD(Entity Relationship Diagram)란 말 그대로 엔터티(Entity)간 관계(Relationship)를 표시한 그림(Diagram)이다.
관계형 DB(RDB, Relationship Database)는 데이터를 중복하지 않고 한 곳에서만 관리하고, 파생되거나 연관성이 있는 데이터를 참조 키로 연결해 필요 시 참조 키로 조인하여(Join) 필요한 데이터를 조회하는 것이다. 그만큼 관계는 ERD의 핵심 요소다.
관계 분석
관계는 엔터티 간 존재하는, 즉 데이터 집합 간 존재하는 연관성을 정해진 표기법(Notation)에 따라 표현하는 것이다.
이 후 연재에서 자세히 알아 보겠지만 엔터티간에는 많은 관계가 존재한다. 이 모든 관계를 다 분석할 필요도 없고, 다 ERD에 표시 할 필요도 없다. 리버스 ERD를 이용한 현행 모델 분석 단계에서는 직접관계만 분석한다.
SNS에서는 아는 사람을 몇 단계만 거치면 미국 대통령과도 관계가 연결된다고 한다. 하지만 데이터모델링에서 관계는 1촌까지만 관리한다. 데이터모델링에서 관계는 마치 점조직과 같아서 바로 옆에 있는 접촉점이 있는 엔터티만 알면 된다. 그 다음 관계는 그 다음 엔터티의 접촉점이 있는 엔터티를 통해 알 수 있다.
직접관계란 말 그대로 엔터티 인스턴스(데이터) 생성에 직접 관련된 관계를 말한다.

[그림 1] 관계 설명 ERD(IE(Information Engineering) Notation으로 표기)
※ [그림 1] ERD는 ERwin R9.x에서 IE(Information Engineering) Notation(표기법)을 사용했다. 관계선 표기법에 대해서는 이후 연재에서 설명한다.
[그림 1] ERD에서 상품판매 엔터티 정의를 '고객에게 자사가 제공하는 유형/무형의 상품을 판매한 내역'이라고 한다면 상품판매 엔터티는 고객 엔터티, 상품 엔터티와 직접적인 관계가 있다. 또한 사원 엔터티도 상품을 판매한 사원으로서 상품판매 엔터티와 직접적인 관계가 있다. 반면 공급처 엔터티는 상품 엔터티와 직접적인 관계가 있으나, 상품판매 엔터티와는 직접적인 관계가 없다. 상품판매 인스턴스는 공급처 없이도 생성되기 때문이다.
그러면 왜 [공급처]→ [상품판매] 관계를 ERD에 표시했을까 결론부터 말하면 표시하지 말아야 할 관계를 표시한 것이다. 상품판매 엔터티에서 공급처번호는 상품판매 엔터티가 본질적으로 가지고 있는 속성이 아닌 상품 엔터티에서 가져온 속성이다(이 후 설명하겠으나 공급처번호는 추출 속성 중 중복 속성에 해당한다.).
만일 상품판매 엔터티에 공급처번호가 없다면 상품에 대한 공급처를 가져오기 위해서는 상품 엔터티와 조인해야 한다. 상품판매 내역 조회 시 상품의 공급처를 포함해 조회하기 때문에 상품 엔터티와 조인을 하지 않으려고 가져다 놓은 속성이다.
직접관계와 대비되는 관계를 간접관계라고 한다. 간접관계는 직접적인 관계가 없는 엔터티의 식별자를 일반 속성으로 갖다 놓음으로써 생기는 관계다. 인스턴스 생성에 관여하지 않는 관계 임으로 제거돼야 한다.
간접관계는 조인 단계를 줄이기 위해 2촌 이상 엔터티 식별자를 일반 속성으로 갖다 놓은 것이다. [그림 1]에서 [공급처]→ [상품판매] 관계가 간접관계에 해당한다. 본질이 아닌 속성을 갖다 놓은 것이기 때문에 추출 속성(Derived Attribute) 가운데 중복 속성이며, 추출 속성 특성상 이 속성을 삭제하더라도 원천만 존재하면 언제라도 재현할 수 있다. 성능 또는 관리상 이유로 제한적으로 허용되기도 하지만, 이러한 간접관계는 ERD에 관계를 표시하지 않는다.
단 ERD는 이해 당사자간 커뮤니케이션 도구 역할도 하기 때문에, 이해 당사자의 모델에 대한 이해를 높이기 위해 ERwin에서는 관계를 Logical Only로, DA#에서는 가상 관계로 표시하여 어떤 엔터티와 간접관계가 있는지 표현할 수 있다(이 방법 또한 이후 연재에서 설명한다.).
분류 기준에 따른 관계 종류를 간단하게 정리하면 [표 1]과 같다.

[표 1] 분류 기준에 따른 관계 종류
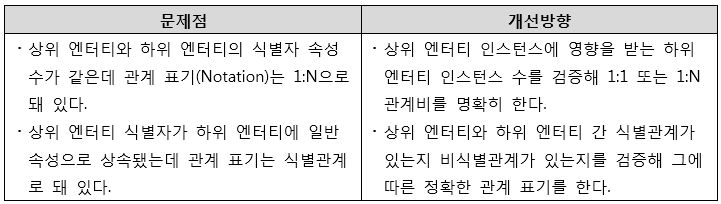
프로젝트 현장에선 관계선이 그어져 있는 ERD를 보기 힘들다. 혹 관계선이 그어져 있더라도 1차원적 관계만 그어져 있고, 중요한 업무 규칙을 반영한 관계가 그어져 있지 않다. 그나마 그어져 있는 관계선도 정해진 표기법(Notation, 식별/비식별, 관계비, Null 옵션 등)과 틀리게 그어져 있는 경우도 많다(두 엔터티의 식별자가 동일한데 관계비(Cardinality)를 1:N으로 한 것 등).
우리는 리버스 ERD를 분석하고 있다. 따라서 아직 ERD에는 관계선이 없는 상태다. 지금부터는 리버스 ERD에서 어떻게 엔터티간 관계를 도출(분석)하는 방법을 설명한다.
앞서 전체 업무의 80%을 담당하는 20% 엔터티에스 ERD에 보기 좋게 엔터티명 또는 테이블명에 공통된 단어가 있는 것끼리 모아 놓고 좌우 정렬한다.
엔터티명 또는 테이블명에 공통된 단어가 있으면 관련성이 높을 수 있다. 많은 사이트에서 테이블명을 부여할 때 특정 규칙에 따라 부여한다. 업무 코드라든지, 같은 업무내에서도 특정 영역을 구분하는 구분자를 테이블명에 포함시킨다. 따라서 현행 테이블 명명 규칙을 사전에 파악해 두어야 한다.

[그림 2] 모델링 Tool 에서 엔터티 정렬 방법
앞서 고객사 담당자로부터 엔터티를 실체·주요·행위·목적으로 분류받았다.
(1) 실체·주요 엔터티 식별자와 주위 엔터티 식별자 간 비교
- 실체·주요 엔터티를 가운데 배치하고 그 주위에 나머지 엔터티를 배치한다.
- 가운데에 있는 실체·주요 엔터티의 식별자와 주위에 있는 엔터티의 식별자와 비교한다.
- 실체·주요 엔터티 식별자명 앞에 수식어를 붙여 사용하는 경우가 있으므로 데이터타입 길이도 감안하여 실체·주요 엔터티와 식별자가 같거나(1:1 관계, 식별자를 구성하는 속성의 명칭, 데이터타입 길이가 같아야 한다.). 실체·주요 엔터티의 식별자 + 추가 속성(1:N 관계)인 것을 찾아 관계선을 맺는다.
- 이때 주의해야 할 것은 관계선을 맺으면 상위 엔터티의 식별자가 하위 엔터티에 상속되면서 하위 엔터티 속성에 FK가 설정되는데, 나중에 검증 시 잘못 맺은 관계선을 삭제하면 하위 엔터티에서 FK 속성이 삭제되고 만다. 이 때문에 ERwin에서는 다대다(Many-to-Many Relationship) 관계선을 사용하고, DA#에서는 가상(Pseudo) 관계선을 사용해 일단 두 엔터티 간 관계가 ‘있는 것 같다’는 것만 표시해 두고 나중에 관계 검증 후 정상적인 관계선을 맺도록 한다.
(2) 실체·주요 엔터티 식별자와 주위 엔터티 일반 속성 간 비교
이번에는 실체·주요 엔터티 식별자와 주위에 있는 엔터티의 일반 속성과 비교한다.
- 기본 적인 방법은 식별자 간 비교하는 것과 동일하다.
- 일반 속성이 많으면 ~번호, ~일련번호, ~식별자, ~코드 속성을 위주로 보면서 실체·주요 엔터티 식별자와 유사한 속성이 있는지 확인한다.
- 용어 표준화가 잘된 모델은 상위 엔터티의 식별자가 하위 엔터티에 상속될 때 속성명을 그대로 사용하거나 '수식어+식별자'로 돼 있어 쉽게 찾을 수 있다. 하지만 우리가 수행하는 대부분의 프로젝트는 용어 표준화가 잘 돼 있지 않거나, 일부 업무에만 적용돼 있는 경우가 많다. 따라서 가운데에 있는 실체·주요 엔터티 식별자 속성과 일반 속성과 데이터타입 길이를 함께 비교해 보고 관계 존재 유무를 판단하도록 한다.
(3) 다른 모델에 있는 엔터티와 관계 찾기 및 ERD 표시 방법
지금까지 같은 모델에 있는 엔터티 중 업무의 80%을 담당하는 20% 엔터티 간 관계를 분석(도출) 했다.
그런데 같은 모델이 아닌 다른 모델에 있는 엔터티를 참조하는 경우는 어떻게 할까 예를 들어 계약 모델에서 상품이나 고객 모델에 있는 엔터티를 참조할 때, 참조하고 있음을 어떻게 확인할 수 있고, 또 그 관계를 ERD에 어떻게 표시할 수 있을까 모든 모델을 다 분석해야 하나 짧은 분석 기간 중 내가 맡은 모델도 분석하기 힘든데 다른 사람이 맡고 있는 모델까지 모두 분석하기 란 불가능에 가깝다.
다른 모델에 있는 엔터티와 관계 분석은 다음과 같이 한다.
- 일단 내가 맡고 있는 모델의 실체 엔터티와 주요 엔터티의 식별자 속성의 의미를 확실하게 파악한다.
대부분 다른 모델에서 참조되는 엔터티는 실체 또는 주요 엔터티이기 때문에 내가 맡고 있는 모델의 실체 엔터티와 주요 엔터티 식별자를 확실하게 파악해 둬야 한다.
- 내 모델에서 다른 모델 엔터티를 참조하는 엔터티 역시 대부분 실체·주요 엔터티다. 다른 모델 엔터티 식별자와 비식별 관계가 있는 경우 다른 모델 엔터티 식별자가 내 모델에 일반 속성으로 상속되기 때문에 내 모델의 실체·주요 엔터티의 일반 속성 중 ~번호, ~식별자, ~코드(개별코드) 속성 또는 이들 속성과 ~일련번호, ~일자, ~구분코드(통합코드) 속성과의 속성 조합을 ERD에 표시해 두고(예를 들어 붉은색·기울임·굵게로 구분한다.) 의미를 파악한다.
- 각자 맡고 있는 모델의 실체·주요 엔터티에 대한 분석이 끝나면, 전체 모델러 회의를 하여 내가 맡고 있는 모델의 실체·주요 엔터티 식별자와 표시해 둔 일반 속성을 식별자로 하고 있는 다른 모델 엔터티가 있는지 크로스 체크한다.
- 모델러 간 크로스 체크로 내가 맡고 있는 모델에 표시한 속성 또는 속성 조합이 다른 모델의 엔터티 식별자와 동일하거나 유사하고 의미가 동일한지가 확인되면, 내가 맡고 있는 모델에 엔터티 명을 '[업무명] + 다른 모델의 참조 엔터티명'으로 하고, 다른 모델의 엔터티에서 식별자(속성 명, 개수, 순서로 똑같이 하여)만 표시한 엔터티를 추가하고, 해당 엔터티와 관계를 맺어 ERD에 표시한다. 이때 ERwin에서는 다대다(Many-to-Many Relationship) 관계선을 사용하고, DA#에서는 가상(Pseudo) 관계선을 사용해 향후 검증 단계에서 관계를 삭제해도 원래 있던 속성이 삭제되지 않도록 한다.
통합코드와 개별코드
코드는 통합코드(공통코드)와 개별코드(목록성코드)로 분류된다.
통합코드 특성은 아래와 같다.
- 코드, 유효값, 유효값명 등 정해진 정보만 관리한다.
- 일반적으로 공통 모델에서 한 엔터티에서 통합·관리된다.
- 유효값 입력·조회는 메타시스템을 통해 이뤄진다.
- 유효값(인스턴스)이 100개 미만이다.
- 일반적으로 코드 앞에 구분·유형·종류·행태·상태 등과 같은 수식어를 붙인다.
예) 고객구분코드, 상품종류코드, 거래종류코드 등
개별코드 특성은 아래와 같다.
- 코드, 유효값, 유효값명 이외의 다양한 부가 정보를 관리한다.
- 부가 정보가 다양해서 하나의 엔터티에서 관리하기 힘들어, 개별 엔터티에서 관리한다. 이 엔터티의 식별자는 ~코드이다.
- 개별코드 엔터티는 오너쉽을 갖는 업무 모델에서 관리된다.
- 유효값 입력·조회는 오너십을 갖는 업무의 화면에서 입력·조회된다.
- 유효값(인스턴스)가 100개 이상이다.
- 일반적으로 구분·유형·종류·행태·상태 등과 같은 수식어를 붙이지 않는다.
예) 부서코드, 증권종목코드, 계정과목코드, 지점코드, 서비스코드 등
다음 [그림 3]은 은행 여신 리버스 ERD에서 실체·주요 엔터티를 중심으로 주위 엔터티 간 관계와 다른 모델 엔터티와의 관계를 분석한 예제다.

[그림 3] 여신 리버스 ERD 관계 분석(도출) 예제 ERD
통합코드와 개별코드
‘한도대출’ 단어가 들어간 엔터티를 실체·주요 엔터티를 중심으로 배치했다.
① 실체·주요 엔터티 식별자와 주위의 엔터티 식별자와 비교해 다대다(Many-to-Many Relationship) 관계선을 사용해 관계를 표시했다.
② 일반 속성 중 ~번호, ~식별자, ~코드 속성 또는 이들 속성과 ~일련번호, ~일자, ~구분코드 속성과의 속성 조합을 ERD에 붉은색과 기울임으로 표시했다.
③ 실체·주요 엔터티 식별자와 주위에 있는 엔터티 일반속성과 비교하여 다대다 관계선을 사용하여 관계를 표시했다.
④ 모델러 간 크로스 체크로 확인된 다른 모델 엔터티를 ‘[업무명] + 엔터티명’으로 하고 식별자만 표시해
⑤ 다대다 관계선을 사용해 관계를 표시했다.
지금까지 리버스 ERD로 관계를 분석하면서 관계로 인한 식별자 상속이 되지 않도록 하고, 나중에 관계 검증 시 관계 삭제로 인한 속성 삭제를 막기 위해 ERwin에서는 다대다(Many-to-Many Relationship) 관계선을 사용하고, DA#에서는 가상(Pseudo) 관계선을 사용했다.
정확하게 관계를 ERD에 표시하기 위해서는 관계비(Cardinality, 카디널리티), 선택성(Optionality, 옵션널리티), 관계차수(Degree, 디그리)를 관계선에 표시해야 하지만 여기서는 엔터티 간 관계가 있다는 것만 분석하기로 하고, 이후 데이터모델링 단계에서 관계 구성 요소를 정확히 ERD에 표시 하도록 한다. 또한 특수한 관계로 재귀 관계(Recursive)와 배타 관계(Exclusive)가 있다.
속성 분석
엔터티에 비해 속성은 수가 너무 많다. 따라서 리버스 ERD 분석에서 속성 하나 하나를 상세하게 분석 하기에는 물리적인 시간이 부족하다.
관계와 마찬 가지로 속성도 전체 업무의 80%을 담당하는 20% 엔터티를 대상으로 속성 분석을 한다.
(1) 속성을 분류한다
이 단계에서 모든 속성을 100% 분류할 수도 없고 그럴 필요도 없다. 여기서는 확실히 식별되는 것만 분류하고 기록한다.
엔터티에는 많은 속성들이 있다. 속성 분류 역시 나 혼자서 한다는 생각에서 벗어날 필요가 있다. 사전에 고객사 담당자에게 20% 엔터티가 정렬된 리버스 ERD를 출력·제공하고 ERD에 중요 속성을 표시해 달라고 하고, 인터뷰를 통해 표시된 속성이 기본·관계·추출·시스템 속성인지 분류 한다.
[표 2]는 속성 종류를 정리한 것이다.

[표 2] 속성 종류
리버스 ERD를 보다 보면 속성이 50개 이상, 많게는 200개가 넘는 엔터티를 종종 볼 수 있다. 간혹 집계나 전문과 같은 목적 엔터티의 속성 수가 50개 이상 될 수는 있지만, 실체·주요·행위 엔터티의 기본 속성은 10~15개 내외다. 많아도 20개를 넘지 않는 것이 일반적이다.
관계 속성은 관계에 의해 또는 조인을 줄이기 위해 추가되는 속성이기 때문에 그리 많지 않다.
시스템 속성은 사전에 정의돼 있기 때문에 쉽게 분류할 수 있다.
문제는 추출 속성인데, 추출 속성을 식별하기 위해서는 엔터티가 관리하는 데이터의 성격을 명확히 파악해야 한다. 이것은 엔터티 정의(Definition)를 정확하게 해야 하는 이유이기도 하다. 상위 엔터티에 있는 속성을 갖다 놓았다고 무조건 추출 속성이라고 할 수 없는 경우도 있다. 또한 계산 속성이라고 해서 무조건 추출 속성이라고 할 수 없는 경우도 있다. 경우에 따라서는 추출 속성으로 보이지만 기본 속성으로 취급해야 하는 경우도 있다. 추출 속성을 식별하기 위해서는 이론적인 배경과 경험이 필요하다.
(2) 미사용 속성을 식별한다
리버스 ERD 분석 단계에서는 미사용 속성을 식별 하도록 한다. 물론 대상 엔터티는 20%에 해당 하는 엔터티다.
그 많은 속성에서 어떤 것이 미사용 속성인지를 식별해 내기란 쉬운 일이 아니다. 고객사 담당자도 중요한 속성은 식별해 줄 수 있으나, 미사용 속성은 바로 식별해 주지 못 한다. 그 이유는 엔터티가 생성된 후 고객사 담당자가 변경됐기 때문에, 엔터티 속성 추가 이력에 대한 기록이 없기 때문에, 최근 몇 년간은 데이터가 입력되지 않았지만 그 이전에는 데이터가 있었기 때문에 등 다양하다.
일단 리버스 ERD 분석에서는 미 사용 속성을 식별하도록 하는데, 유의 해야할 것은 이번에 미 사용으로 식별되더라도 이후 데이터모델링 단계에서 사용으로 바뀔 수 있으니 리버스 ERD에서 삭제는 하지 말고 아래 [그림 4]에서와 같이 ERD에 표시를 해두도록 한다.
통합코드와 개별코드
- 미 사용 속성은 속성 뒤에 (x)를 붙여 표시한다.
- 추출 속성은 속성 뒤에 (d)를 붙여 표시한다.
- 시스템 속성은 속성 뒤에 (s)를 붙여 표시한다.
- 관계 속성은 속성 뒤에 (r)를 붙여 표시한다.

[그림 4] 추출·시스템·미사용 속성 표시 ERD
지금까지 리버스 ERD로부터 엔터티, 식별자, 관계, 속성을 분석하였다. 분석을 하면서 현재 모델의 문제점을 파악할 수 있었다. 다음 연재에는 파악한 문제점으로부터 TO-BE 모델의 개선방향을 정의하고 고객의 요구사항을 관리하는 방법을 설명하겠다.
현행 모델의 문제점으로부터 개선방향을 도출하고 고객 요구사항을 정리해, 고객과 이해 관계자에게 TO-BE 모델의 방향성을 제시한다.
개선방향 정의
지난 회에는 리버스 ERD로 엔터티, 식별자, 관계, 속성을 분석했다. 이 분석을 통해 현행 데이터 모델에 있는 문제점을 발견할 수 있었다. 이번 회에는 이 문제점을 데이터 모델 이론과 각 프로젝트에서 세운 데이터 모델 원칙에 입각해 어떻게 개선할 것인가를 알아본다.
모델의 구성요소인 엔터티, 식별자, 관계, 속성을 상위 카테고리로 하고 토픽별로 정리해 발견된 문제점과 이를 어떻게 개선해야 하는지와 어떤 시사점이 있는지 기술한다.
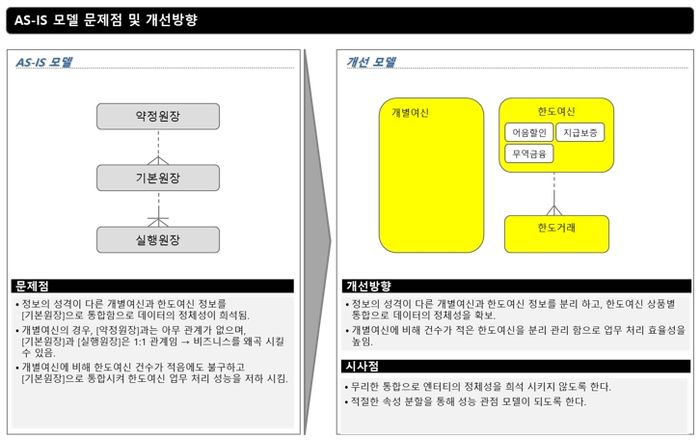
[그림 1] AS-IS 모델 문제점과 개선방향 PPT 예제
[그림 1]은 AS-IS 모델의 문제점에 대한 개선 모델과 TO-BE 모델의 방향성 수립 시 고려해야 할 것을 정리한 예제다.
다소 차이는 있으나 다수 프로젝트에 공통적으로 발견되는 문제점과 개선방향을 정리해 보았다.
1. 엔터티
- 동일 데이터 엔터티의 중복 관리

[표 1] 분류 기준에 따른 관계 종류
프로젝트 현장에선 관계선이 그어져 있는 ERD를 보기 힘들다. 혹 관계선이 그어져 있더라도 1차원적 관계만 그어져 있고, 중요한 업무 규칙을 반영한 관계가 그어져 있지 않다. 그나마 그어져 있는 관계선도 정해진 표기법(Notation, 식별/비식별, 관계비, Null 옵션 등)과 틀리게 그어져 있는 경우도 많다(두 엔터티의 식별자가 동일한데 관계비(Cardinality)를 1:N으로 한 것 등).
우리는 리버스 ERD를 분석하고 있다. 따라서 아직 ERD에는 관계선이 없는 상태다. 지금부터는 리버스 ERD에서 어떻게 엔터티간 관계를 도출(분석)하는 방법을 설명한다.
앞서 전체 업무의 80%을 담당하는 20% 엔터티에 집중하기로 했다. 20%에 해당되는 엔터티를 리버스 ERD에 보기 좋게 엔터티명 또는 테이블명에 공통된 단어가 있는 것끼리 모아 놓고 좌우 정렬한다.
엔터티명 또는 테이블명에 공통된 단어가 있으면 관련성이 높을 수 있다. 많은 사이트에서 테이블명을 부여할 때 특정 규칙에 따라 부여한다. 업무 코드라든지, 같은 업무내에서도 특정 영역을 구분하는 구분자를 테이블명에 포함시킨다. 따라서 현행 테이블 명명 규칙을 사전에 파악해 두어야 한다.

[그림 2] 동일 데이터 엔터티 중복 관리 개선방향

- 엔터티 정의에 맞지 않는 속성 관리

- 부정확한 엔터티명 및 업무간 엔터티명 중복

- 유연성과 확장성 부족

[그림 3] 유연성과 확장성 부족 개선방향

- 서브타입 오류

2. 식별자
- 서브타입 오류

[그림 4] 식별자 부재 개선방향

- 정확하지 않은 식별자

[그림 5] 정확하지 않은 식별자 개선방향

- 부적합한 식별자 명칭

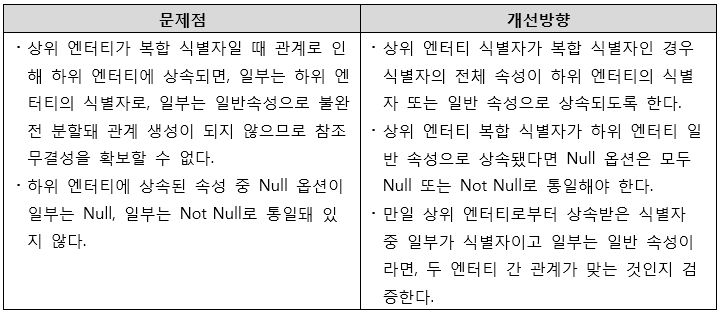
- 복합 식별자 상속 순서 오류

[그림 6] 복합 식별자 상속 순서 오류 개선방향

- 복합 식별자 분할 상속 오류

[그림 7] 복합 식별자 분할 상속 오류 개선방향
- 식별자 명칭 유일성 부재

[그림 8] 식별자 명칭 유일성 부재 개선방향

3. 관계
ERD에 관계가 없는 엔터티가 많으므로 ERD에 표시된 관계를 기준으로 개선방향을 도출한다.
- 관계 표기(Notation) 오류

[그림 9] 관계 표기 오류 개선방향
- 업무 프로세스를 관계로 표현 오류

[그림 10] 업무 프로세스를 관계로 표현해 오류 개선

- 배타 관계 표시 부재

[그림 11] 배타 관계 표시 부재 개선방향

※ 배타 관계(Exculsive Relationship): 엔터티가 두 개 이상의 상위 엔터티와 관계를 갖는데, 그 관계는 동등하며 상호 배타 적일 때의 관계를 말한다. 하위 엔터티 인스턴스는 두 개 이상의 상위 엔터티 중 한 상위 엔터티와만 관계를 갖는다.
4. 속성
- 반복 속성

[그림 12] 반복 속성 개선방향

- 무분별한 추출(Derived) 속성

[그림 13] 무분별한 추출(Derived, 중복) 속성 개선방향

- 한 엔터티에 너무 많은 속성 존재

[그림 14] 한 엔터티에 너무 많은 속성 존재 개선방향

- 속성 표준화 미 적용

- 코드 표준화 미비

[그림 15] 코드 표준화 미비 개선방향

이상과 같이 엔터티, 식별자, 관계, 속성별 문제점에서 도출한 개선방향을 종합해 TO-BE 데이터 모델에 대한 방향성을 수립한다.

[그림 16] TO-BE 데이터 모델링 방향성 예시
이렇게 수립한 'TO-BE 데이터모델 방향성'은 헌법과 같은 역할을 한다. 프로젝트뿐 아니라 프로젝트 종료 후에도 전사 차원의 원칙으로 잡고, 이후 진행되는 프로젝트에서 데이터 모델링의 기본 원칙으로 활용한다.
지금까지 현행분석 단계에서 해야 할 것을 소개했다. 다음 연재부터 본격적으로 데이터 모델링을 다루겠다.
지금까지 현행모델분석을 어떻게 하는지 살펴보았다. 프로젝트가 시작되면 내가 만나야 할 사람, 나와 같이 일을 할 사람을 찾는다. WBS(Work Breakdown Structure)를 작성해 누가·언제·어떤 일을 해야 하는 지와 일의 선후관계를 계획한다.
AS-IS 리버스 ERD로 현행 분석
현행 ERD와 테이블·컬럼 정보 등의 AS-IS 자료를 수집한다. ERD가 있다면 현행화 정도를 파악한 후 수집한 테이블·컬럼 정보와 비교한 후 추가·삭제·변경된 내용을 ERD에 반영한다. ERD가 존재하지 않거나 있더라도 현행화돼 있지 않다면 수집한 테이블·컬럼 정보로 AS-IS 리버스 ERD를 작성한다.
AS-IS 리버스 ERD에서 엔터티를 실체·주요·행위·목적 엔터티로 고객사 담당자와 함께 분류해, 80% 업무를 담당하고 있는 20% 엔터티에 해당하는 실체와 주요 엔터티를 파악한다. 우선 실체·주요 엔터티에 대한 정체를 정의(Definition)한다. 고객사 담당자와 함께 어떤 데이터를 관리하는지, 업무적 특성은 무엇인지, 사용 빈도는 어떻게 되는지, 관련된 엔터티는 어떤 것이 있는지, 당장 말해 줄 수 있는 중요한 속성은 무엇인지를 빠르게(Quick) 파악한다.
AS-IS 리버스 ERD로 현행 주 식별자가 유일성·최소성·안전성(불변성)·활용성·최소길이·고정길이·비암호화 원칙에 부합하는지를 분석한다. 식별자가 엔터티에서 관리하는 데이터를 대표하는지를 분석한다.
AS-IS 리버스 ERD에는 아직 관계선이 없는 상태다. 우선 실체·주요 엔터티를 대상으로 엔터티명 또는 테이블명에서 공통된 단어가 있으면 관련성이 있을 수 있다. 따라서 이런 엔터티들을 ERD에 모여 놓고 엔터티간 식별자↔식별자, 식별자↔일반속성 간을 비교해 임시로 관계를 도출한다. 정확한 관계비(Cardinality), 선택성(Optionality), 관계차수(Degree)는 향후 본격적인 데이터모델링 단계에서 파악한다.
AS-IS 리버스 ERD를 이용해 속성을 분석한다. 80% 업무를 담당하는 20% 엔터티만 하더라도 엔터티 개수에 비하면 속성 개수는 엄청 많으므로 모든 속성을 다 분석할 수 없다. 확실히 식별되는 것만 분석한다. 고객사 담당자의 도움을 받아 속성을 기본·관계·추출·시스템 속성으로 분류한다. 또한 미사용 속성을 식별하되 ERD에서 삭제하지 말고 속성 뒤에 (x)로 표시해 둔다. 추출 속성은 뒤에 (d)를, 관계 속성 뒤에 (r)을, 시스템 속성은 뒤에 (s) 등을 붙여 ERD에 표시해 둔다.
AS-IS 리버스 ERD로 엔터티·식별자·관계·속성 분석을 통해 파악된 문제점으로부터 개선 방향을 도출하고 이로부터 TO-BE 데이터모델링 원칙을 수립한다. 이제부터 본론으로 들어가보자.

[그림 1] 데이터 모델링 단계와 해야 할 일
[그림 1]을 기억하는가 1회 연재에서 보았던 그림이다. 연재를 이 그림을 토대로 진행하고 있다. 이 그림에서 다음 단계는 개념 모델링이다.
대부분의 데이터 모델링 책에서는 데이터 모델을 개념 데이터 모델(Conceptual Data Model), 논리 데이터 모델(Logical Data Model), 물리 데이터 모델(Physical Data Model)로 분류하고 있다.
이런 분류가 전적으로 옳다. 각 모델은 의미와 활용 분야가 있다.
개념·논리·물리 모델을 구분할 시간이 없는 현장
하지만 사선(死線)과 같은 프로젝트 현장에서 짧은 기간 동안 개념·논리·물리 모델을 구분하면서 작성할 시간적 여유가 없다. 최대 300~400명이 투입되는 차세대급 프로젝트에서도 분석·설계 단계는 6~7개월 정도다. 이 기간 동안 교과서적으로 개념 모델 따로, 논리 모델 따로, 물리 모델 따로 작성하자고 주장하는 사람은 연구소로 가야할 사람이거나 프로젝트호를 산으로 향하게 하는 스파이로 몰릴 수 있다().
PMP(Project Management Professor)로서 저자가 확언하는데 프로젝트란 유일무이한 것을 만드는 것이다. 우리가 IT 프로젝트를 한다는 것은 세상에 없던 전산 시스템을 구축하는 일이다. 구축된 전산 시스템과 똑 같은 것은 다시는 만들 수 없다. 만일 똑 같은 시스템을 계속 만드는 일을 한다면 그건 프로젝트를 하는 것이 아니라 솔루션 패키지를 개발하는 것이다.
저자가 참여한 몇몇 프로젝트에서 프로젝트로 만든 시스템을 다른 동종 업체에 서비스하겠다고 모든 엔터티 첫 번째 식별자 속성으로 ‘회사구분코드’를 포함시켰다. 하지만 결국 ‘회사구분코드’ 에는 같은 값만 입력되고 그 시스템을 이용하는 동종 업체는 없었다. 동종 업체라 하더라도 개괄적인 업무 프로세스와 데이터는 비슷하지만, 세부적인 업무 프로세스와 데이터가 다르기 때문이다. 다른 프로젝트에서는 기존에 모든 엔터티에 있던 ‘그룹회사코드’를 제거하기도 했다.
IT 프로젝트에서 구축하려는 시스템은 이미 그 목적과 용도가 확정돼 있다. 이 목적과 용도에 맞게 모든 하드웨어, 소프트웨어, 데이터베이스, 네트워크, 프로세스를 구축한다. 따라서 IT 프로제트에서 데이터 모델은 개념·논리·물전 과정을 통해 상세화하고 구체화하는 것이다. 단지 관리적인 측면에서 데이터 모델을 개념·논리·물리 단계로 구분한다.
전사적 개념모델이 필요한 이유
필자 개인적으로 전사적인 개념 모델은 반드시 있어야 한다고 본다. 업무별로 작성된 개념 모델을 통합하면 기업에서 다루는 데이터 지형도가 된다.
고객과 미팅하러 고객사를 방문한다. 첫 방문 때는 주소만 알고 있다. 스마트폰에서 지도 앱을 켜서 찾아간다. 건물 로비에 도착한다. 층별 입주 업체 현황을 보여주는 안내판을 보고 고객사가 몇 층에 있는지 확인한다. 엘리베이터를 타고 해당 층으로 올라간다. 해당 층에 내렸더니 친절하게도 엘리베이터 옆 벽면에 해당 층 안내도에는 현재 위치까지 표시돼 있다. 현 위치에서 오른쪽으로 네 번째가 고객사 사무실임을 확인하고 발길을 옮긴다.
전사 개념 모델에는 우리 회사에서 어떤 데이터를 관리하고 있으며 데이터 간 관계가 있는지 표시돼 있다. 전사 개념 모델을 보면 내가 필요한 데이터가 있는지를 확인할 수 있고, 그 데이터를 획득하기 위해서는 어떤 업무(또는 주제영역)에서 확인해야 하는지 쉽게 알 수 있다. 좀더 자세하게 확인하려면 해당 업무(또는 주제영역) 논리 모델을 보면 된다.
이전 3·4회 연재 ‘리버스 ERD를 이용한 분석’에서는 모든 엔터티에 집중하지 않았다. 대신 80% 업무를 담당하고 있는 20% 엔터티에 집중했다. 이 20%에 해당하는 엔터티 에도 80대 20 법칙이 적용된다. 20%에서 다시 20%에 해당하는 엔터티와 식별자·관계·주요속성을 그려 놓은 게 개념모델이다.
은행을 예를 든다면 공통·고객·상품·여신·수신·외환·대행·회계 등의 업무가 있다. 800~900개 정도의 테이블이 있다. 전체 800개 테이블이 있다 하고, 이중 20%는 160개다. 160개 중 20%는 32개이다. 이 32개 엔터티에 대한 식별자·관계·주요속성만 그려져 있는 모델만 있어도 어떤 데이터를 관리하고 있으며 어떤 데이터를 어디서 찾아야 할지 한눈에 확인할 수 있다(관점에 따라서는 개괄모델이라도 할 수도 있다).
현장 프로젝트에서는 개념·논리·물리 모델을 정확히 구분하지는 않는다. 다만 프로젝트 관리적인 목적으로 분석 단계에는 논리 모델로 설계 단계에는 물리 모델로 호칭한다.
이론적으로 논리 모델과 물리 모델은 전혀 다른 모습이 될 수도 있다. 논리 모델은 논리적인 데이터와 관계를 표시하고, 물리 모델은 어떤 DBMS(Database Management System)를 사용하는지에 따라 달라진다. 예를 들어 파티션을 지원하지 않는 DBMS라면 논리 모델에서 1개 엔터티를 물리 모델에서는 파티션 키별로 여러 개 테이블로 분리해야 한다.
동시 다발적으로 진행되는 데이터 모델링
논리 모델에서는 두 개 엔터티로 분리했지만, 물리 모델에서는 두 테이블이 한꺼번에 조회되는 쿼리가 대다수라서 조회 성능 향상을 위해 한 개 테이블로 통합하기도 한다. 반대로 논리 모델에서는 한 개 엔터티인데, 물리 모델에서는 컬럼 수가 많고 자주 조회되는 컬럼과 자주 조회되지 않는 컬럼, 업데이트가 빈번한 컬럼과 그렇지 않는 컬럼 등을 분리해 각 테이블로 분리하기도 한다.
그런데 현장 프로젝트는 제안 단계부터 DBMS를 확정하고 프로젝트를 진행한다. 만일 프로젝트 중간에 DBMS를 교체하면 프로젝트 접어야 할 수도 있다. DBMS는 확정되었기 때문에 확정된 DBMS의 특성에 따라 논리 모델 단계부터 통합할지 분리할지를 결정한다. 또한 기존 데이터가 존재하므로 기존 데이터를 분석하면 논리 모델 단계부터 통합할지 분리할지 결정할 수 있다.
이렇듯 현장 프로젝트에서는 개념·논리·물리 모델 구분 없이 엔터티·식별자·관계·속성을 도출하고 표준화를 적용한다. 선정된 DBMS에 맞춰 엔터티를 분할/통합하며, 현재 데이터 양과 액세스 패턴을 고려해 상당한 역정규화를 동시에 진행한다.
[그림 1]의 개념모델링·논리모델링·물리모델링에서 해야 하는 것이 순차적이 아닌, 동시 다발적으로 진행된다. 이렇게 할 수밖에 없는 이유는 분석·설계 기간이 짧고, 전문 모델러가 투입되지 않기 때문이다.
개념·논리·물리 모델로 분리해 진행하기 위해서는 전문 모델러가 투입돼야 하는데 현장 프로젝트에서는 비용 문제로 전문 모델러 대신 개발팀의 설계자 중 경험이 많은 개발자가 데이터 모델링을 한다. 개발팀 입장에서는 빨리 개발해야 하기 때문에 모델링 원칙, 확장성, 유연성, 정규화와 표준화를 정확히 적용하지 않고 데이터 모델링을 진행한다. 그래서 속성이 200개가 넘는 엔터티, 식별자가 없는 엔터티, 식별자 수가 10개가 넘는 엔터티, 관계 없는 ERD가 만들어 진다.
이 글은 전문 모델러가 아닌 일반 개발자가 '업무가 정확히 담겨 있고 모두가 이해할 수 있는 모델'을 만들 수 있게 하기 위함이다. 따라서 편의상 개념·논리·물리를 하나로 묶어 엔터티·식별자·관계·속성에 대한 꼭 알아야하는 모델링 이론과 팁을 설명한다.
또 데이터 모델링을 하면서 반드시 알아야 하는 데이터 표준화(단어, 용어, 도메인)와 공통 데이터 모델링을 하기 위한 모델링 표준에 대해 설명한다. 더불어 작성한 데이터 모델에 대한 품질을 점검하는 방법에 대해 설명한다.
데이터 모델이란
데이터 모델의 사전적 정의는 다음과 같다.
데이터 모델링은 기업 등의 조직에서 관리할 데이터 집합을 찾아 정의하고, 정의된 데이터 집합 간에 존재하는 업무 규칙과 데이터를 구성하는 세부 항목을 정해진 표기법(Notation)을 이용해 모형으로 시각화하는 과정이며, 이 과정의 산출물이 데이터 모델(Data Model)이다.
‘데이터 집합’은 엔터티이며, ‘업무 규칙’은 관계이며, ‘세부 항목’은 속성이며, ‘시각화하는 과정’은 개념·논리·물리 모델링이다.

[그림 2] 데이터 모델 요소
일상에서 모델(Model)이라면 패션 모델 또는 모델 하우스, 자동차 모터 쇼를 연상하게 된다. 패션 모델은 디자이너가 옷과 모자, 핸드백, 액세서리를 생산에 앞서 전문 훈련을 받은 패션 모델을 통해 선보임으로써 일반인이 ‘내가 저 옷, 모자, 핸드백, 액세서리를 착용하면 저렇게 되겠구나’ 하는 생각을 불러일으킨다.

[그림 3] 아파트 모델 하우스 조감도와 평면도
모델 하우스는 아직 아파트가 실재하지는 않지만, 어떤 모습과 환경으로 시공사가 아파트를 건설할 것인가에 대한 정보를 제공한다.
자동차 모터 쇼에서도 자동차 제조사가 콘셉트카를 선보여 미래의 자동차에 적용되는 기술과 디자인을 예측하도록 한다.
이와 같이 모델이란 어떤 대상에 대한 쉽게 이해하고 파악할 수 있는 정보를 제공한다. 특히 데이터 모델은 현실세계에 대해 우리가 관심있어 하는 대상을 데이터베이스화하기 위한 개념적 도구다.
개념·논리·물리 모델과 추상화
현장 프로젝트에서는 개념·논리·물리 모델의 명확한 구도 구분 없이 설명하기로는 했다. 하지만 각 모델에 대한 정의와 활용 방안은 알고 넘어가도록 하자.

[표 1] 개념 논리 물리 모델 설명
데이터 모델링에서 추상화라는 말이 자주 나온다. 추상화의 사전적 정의는 아래와 같다.
추상화는 컴퓨터 과학 분야에서 주어진 문제나 시스템의 복잡도를 단순화해 인식하기 쉽게 만드는 개념화 작업. 핵심 요소를 잘 파악해 필요 이상으로 상세, 복잡한 요소들을 결합하거나 단순화하고, 속성의 일부분만으로 주어진 대상을 간결하고 명확하게 표현한다. 복잡도를 관리하는 핵심 기술이라고 할 수 있다. (출처: IT용어사전)
알 듯 모를 듯한 정의다. 간단하게 설명하자면 추상화란 군더더기는 모두 빼고 대상이 갖고 있는 핵심만 표현함으로써 대상을 빠르고 직관적으로 인식하도록 하는 것이다.

[그림 5] 여러 가지 표지판

[그림 6] 추상화한 수도권 지하철 노선도
[그림 5]와 [그림 6]에서 보듯이 대상의 핵심만을 표현함으로써 대상을 더 명확히 이해하도록 한다. 데이터 모델에서 추상화란 현실 세계에서 다루는 데이터를 관련자들이 이해할 수 있도록 도식화하는 것이다.
데이터 모델이란 현실 세계에 존재하는 있는 유무형의 고객, 사원, 상품, 서비스, 계약, 계좌, 카드, 거래, 조치 등의 데이터를 모델, 주제영역, 엔터티, 식별자, 속성, 관계라는 데이터 모델 요소로 추상화해 관련자들이 이해할 수 있도록 도식화한 것이고, 그 과정이 데이터 모델링이다.
주제영역은 데이터간 상호 관계가 높은 엔터티들을 모아 놓은 논리적 구분 단위다.
1,000개의 엔터티가 있는 모델을 A3 용지 한 장에 다 표현할 수 있을까 혹 가능하더라도 너무 작아서 잘 보이지 않거나, 엔터티 간 관계 표현이 복잡해서 가독성이 떨어질 것이다. 대신에 A3 용지 여러 장에 20~40개 정도로 엔터티를 그룹핑해 보면, 적당한 크기의 관계도를 읽기에 편할 만큼 표현할 수 있을 것이다.
이렇듯 전체 엔터티를 관리하기 쉽게 그룹핑해 놓은 것이 주제영역이다. 그럼 어떻게 엔터티를 그룹핑하면 좋을까 엔터티명을 가나다 순으로 배치한 다음, 20개씩 그룹핑하면 될까 물론 아니다. 데이터 성격이 유사한 엔터티끼리 그룹핑하는 것이 효과적이다. 다시 말하면 데이터 간 상호관계가 밀접하고 다른 주제영역과는 독립적인 엔터티를 그룹핑하는 것이 주제영역이다.
주제영역을 정의하는 가장 큰 목적은 데이터의 계층적 구조를 파악해 관리할 수 있기 때문이다. 수많은 데이터를 사전 정의된 기준에 따라 분류해 놓음으로써 데이터에 대한 접근성을 높이고, 신규 데이터 발생 시 분류와 관리를 용이하게 할 수 있다.
주제영역 정의
- 데이터 간 상호관계가 밀접하고 다른 주제영역과는 독립적인 엔터티를 그룹핑하는 것이 주제영역(Subject Area)이다.
- 주제영역은 데이터간 상호 관계가 높은 엔터티들을 모아 놓은 논리적 구분 단위다.
- 주제영역은 데이터로 관리하고자 하는 관심 영역으로, 데이터의 상위 집합이다.
- 하나의 주제영역으로 정의되는 데이터 간의 관계는 밀접하고, 다른 주제영역에 포함되는 데이터 간의 상호작용은 최소화할 수 있도록 정의한다(높은 응집성, 낮은 결합성).

데이터 위치를 쉽게 찾고 신규 데이터를 분류하는 기준
책을 빌리기 위해 도서관 도서 검색대에서 원하는 책을 대출할 수 있는지를 조회한다. 다행히 대출가능하면 ‘331.5412-ㅂ986ㅂ’라고 표기된 청구기호를 종이에 적거나 인쇄한다.

[그림 1] 청구기호와 도서관 책장
책마다 배정된 청구기호는 자료의 위치를 알려주고, 다른 자료와 구분해 주는 역할을 한다. 따라서 청구기호는 책들의 주소라고 할 수 있다.
청구기호 앞 3자리를 보고 어느 책장에 있는지 먼저 찾는다. 그리고 해당 책장에 저자기호 순으로 책이 비치돼 있으므로 저자기호를 보고 순차적으로 오른쪽에서 왼쪽으로, 위에서 아래로 훑어보며 책을 찾을 수 있다.
청구기호 중 앞 3자리를 분류기호라고 한다. 한국십진분류법을 토대로 000부터 999번까지 책이 주제별로 구분돼 있다. 청구기호를 토대로, 분류기호가 찾고자 하는 책의 위치를 알려주므로 책을 쉽게 찾을 수 있다. 또한 신규 도서의 주제에 맞게 분류기호를 부여함으로써 신규 도서 분류를 쉽게 해 준다.
분류기호로 책의 위치를 쉽게 찾듯이, 데이터 주제영역은 찾고자하는 데이터의 위치를 쉽게 찾을 수 있도록 한다. 또한 신규 데이터를 신속하게 분류하는 기준도 제공한다.
데이터 성경 중심과 업무조직 중심 주제영역
원칙적으로는 데이터 성격을 기준으로 엔터티를 그룹핑해 주제영역을 정의해야 한다. 하지만 실무 프로젝트에서는 기업의 업무조직으로 주제영역을 정의하는 것이 일반적이다. 데이터의 유사성도 중요하지만, 해당 주제영역에 대한 오너십(데이터에 대한 권한과 책임) 문제가 기업 조직 구조와 맞물려 있어 데이터 성격을 기준으로 주제영역을 정의하기에는 괴리가 있다.
예를 들어 은행에서 데이터 성격을 기준으로 주제영역을 정의한다고 하자. 여신·수신·외환·대외 업무조직에서 고객과 체결한 계약 데이터를 묶어 ‘계약’이라는 주제영역을 정의했다. 하지만 여신·수신·외환·대외 업무조직은 있지만 ‘계약’이라는 업무조직은 없다. 각 업무조직에서 발생한 계약 건은 각 업무조직에서 체결과 실행에서 종료까지 관리하는 것이 일반적이다. 전사에서 발생한 계약 건을 총괄 관리하는 업무조직을 별도로 만들지 않는다면 ‘계약’ 주제영역의 데이터를 누가 관리하고, 누가 권한과 책임질 것인지가 명확하지 않게 된다. 즉 ‘계약’ 주제영역에 있는 ‘계약기본’ 엔터티에는 여신·수신·외환·대외에서 발생한 데이터가 들어 있다. 그럼 어느 업무에서 ‘계약기본’ 엔터티를 관리할 것인가

[그림 2] 업무조직 중심 주제영역 정의 vs. 데이터 성격 중심 주제영역 정의
[그림 2]는 업무조직 중심의 주제영역과 데이터 성격 중심의 주제영역을 표현한 것이다.
2000년도 초로 일반화한 참조 모델을 소개하면서 데이터 주제영역을 업무관계자(Party), 계약(Agreement), 상품(Product), 경영방침(Business Direction), 자원(Resource), 이벤트(Event), 장소(Location), 조건(Condition), 분류(Classification) 등으로 분류하는 방법을 소개했다. 국내 SI 업체들에서 이것을 그대로 받아들여 프로젝트를 진행한 적이 있었다. 처음에는 데이터 성격 중심의 주제영역이 주는 이점을 부각시키면서 진행했다. 하지만 프로젝트가 진행되면서 데이터에 대한 오너십이 기존 업무조직과 배치(背馳)됐다. 업무조직을 바꾸지 않는 이상 데이터에 대한 오너십 문제를 해결할 수 없었다. 이 때문에 다시 업무조직 중심의 주제영역으로 회귀한 적이 있다.
데이터를 의미적으로 일반화해 그룹핑하면, 유연한 데이터 구조와 데이터 통합 및 공유 측면에서 효과적이다. 하지만 기업의 업무적 가시성 확보가 어렵고 업무간 오너십 문제가 발생할 수 있으므로 실무 프로젝트에서는 데이터 성격 중심과 업무조직 중심을 적절히 적용해 주제영역을 정의해야 한다.

[그림 3] 데이터 성격 중심과 업무조직 중심을 적절히 반영한 주제영역 정의
[그림 3]은 데이터 성격 중심과 업무조직 중심 주제영역을 적절히 반영한 주제영역 정의 예시다.
[그림 3]에서 데이터 성격 중심 주제영역은 업무를 수행하는 주체·대상·자원 등과 관련된 데이터로 고객·상품·조직 같은 주제 영역이 이에 해당한다. 엔터티 분류에서 실체 엔터티에 해당되는 엔터티가 주로 포함돼 있다. 정의(Definition)에 의한 데이터가 관리된다.
[그림 3]에서 업무조직 중심 주제영역은 여러 가지 업무 활동에 의해 발생하는 계약·거래·주문·결제 등과 같은 데이터를 업무조직별 분류로 이뤄졌다. 같은 계약 데이터라도 그 데이터의 오너십이 어느 업무에 있는지에 따라 여신·수신·대외 등으로 분류된다.
실무 프로젝트에서 목표 주제영역 설계
데이터 주제영역을 설계하기 위해서는 먼저 모든 엔터티를 파악해야 한다. 모든 엔터티를 정의하면서 유사한 엔터티를 분류·그룹핑하는 과정을 거치면서 주제영역을 설계한다. [그림 3]은 일반적인 데이터 주제영역 설계 절차다.

[그림 4] 일반적인 데이터 주제영역 설계 절차(출처: dbguide.net)
수행 프로젝트에서 분석 단계 초반에 주제영역을 설계해야 한다. [그림 4]와 같은 절차로 주제영역을 설계하기에는 기간이 너무 짧다. 분석 단계(3~4개월)를 온전히 주제영역 설계에만 할애한다면 가능할 수도 있지만, 분석단계에서 제출해야 여러 산출물을 고려할 때 일반적이 방법으로 주제영역을 설계하기란 쉽지 않다.
EA·ISP 컨설팅 산출물 참고
어느 정도 규모가 되는 프로젝트는 개발 프로젝트 전에 EA(Enterprise Architecture) 컨설팅이나, ISP(Information Strategy Plan) 컨설팅을 한다. 컨설팅 업체에서 AA(Application Architecture), TA(Technical Architecture), DA(Data Architecture), BA(Business Architecture) 분야별로 TO-BE에 대한 큰 그림을 제시한 산출물을 만든다.
필자도 EA·ISP 컨설팅에 참여했지만 개발 프로젝트 조직에서 받아서 바로 쓸 수 있을 만한 수준으로 산출물을 만들기에는 기간과 인력이 턱없이 부족했다. 어찌 보면 너무 원칙 수준이기도 하고, 수박 겉 핥기식이기도 하지만, 해당 기업의 고민과 문제점, 나아갈 방향(TO-BE)을 컨설턴트들과 기업 핵심 인력이 머리를 맞대고 고민한 흔적은 엿볼 수는 있다.
따라서 EA·ISP 컨설팅 자료에서 AS-IS의 문제점과 TO-BE 방향성을 참고하도록 한다.
TO-BE AA 기능 구조 참고
위에서 살펴봤지만, 실무 프로젝트에서는 데이터 주제영역을 데이터 성격 중심과 업무조직 중심을 적절히 조정해 주제영역을 정의한다. 일반적으로 애플리케이션 기능 구조는 업무조직에 맞춰 설계하므로 ‘업무조직’은 TO-BE AA(Application Architecture) 기능 구조를 참조한다.
동종업종 타사의 주제영역 참조
같은 업종에서 다루는 데이터는 유사하다. 마이너 데이터는 다소 다를 수 있지만, 데이터 주제영역을 분류에 사용되는 메인 데이터는 유사하다. 따라서 동종 업종의 타사 주제영역을 참조한다.
현행 데이터 구조 분석
현행 데이터에 대한 구조 분석은 TO-BE 데이터 주제영역을 설계하는 데 가장 중요한 활동이다.
‘백문이 불여일견’이라고 남의 자료를 참고하더라도 내가 보고, 분석하고, 문제점을 파악하여 TO-BE 개선점을 도출한 것만큼 데이터 주제영역을 설계하는 데 중요한 인풋은 없다.

[그림 5] 실무 프로젝트에서 목표 주제영역 설계
[그림 5]는 실무 프로젝트에서 목표 주제영역 설계 방법을 도식화한 것이다.
EA·ISP 자료, TO-BE 목표 AA 기능 구성, 타사 모델을 참고하고 현행 데이터 구조를 분석해 문제점과 개선방향을 확인한다. 이어서 해당 기업의 특성과 일반적인 주제영역 분류 원칙, 구성 방법을 적용해 TO-BE 목표 주제영역을 설계한다.
'Biz > Modeling' 카테고리의 다른 글
| Data Vault Modeling (2) | 2024.09.05 |
|---|---|
| 노찬형의 제로에서 시작하는 데이터 모델링 시즌II (0) | 2024.07.05 |
| DA# 다중 물리모델 설계 (0) | 2016.07.02 |
| DA# 4 표기법 (0) | 2016.06.25 |
| DA# 3리버스 (0) | 2016.06.18 |




댓글